
Overview
EMERSE uses Solr to search and retrieve documents, and all documents and document metadata are stored in the file structure of the Solr indexes. All other data are stored and retreived from a relational database. This includes patients (names, demogreaphics), patient lists, Term bundles, auditing and user information. This document highlights a few areas within the data model, but a full data dictionary is available if more detail is desired.
| The data for the documents and document indices are not stored within this database. Instead these are managed by Solr in its own data store and can be on a separate server from the Oracle database. |
Patient Demographics
PATIENT table
Table: PATIENT
Population: From external source (such as EHR)
Population Frequency: Can be variable, but once per day is reasonable
The EMERSE schema includes a patient table with medical record number (MRN), name, date of birth, and other demographic information which is displayed in the search results. Data in this table is used to display the patient name, validate user-entered or uploaded MRNs and to calculate current ages of the patients. Other demographic dta are used to summarize the populations found in a search.
| Although the coded demographics information is not required, some features such as the demographics breakdowns within the all patient search feature will not work if sex, race, ethnicity are not populated. |
| For all documents indexed, there must be a corresponding patient in the patient table with a medical record number (MRN) that matches the document. This should be taken into consideration when determining the frequency for updating this table. |
| Column name | Description | Required or Optional |
|---|---|---|
id |
Primary Key |
Required |
external_id |
Medical Record Number |
Required |
first_name |
First Name |
Required |
middle_name |
Middle Name |
Optional |
last_name |
Last Name |
Required |
birth_date |
Birth Date — used to calculate current age |
Required |
sex_cd |
Sex |
Optional |
language_cd |
Language |
Optional |
race_cd |
Race |
Optional |
marital_status_cd |
Marital Status |
Optional |
religion_cd |
Religion |
Optional |
zip_cd |
ZIP code |
Optional |
create_date |
Date the row was created. Can be used to track changes to the table. |
Optional |
update_date |
Date the row was updated. Can be used to track changes to the table. |
Optional |
deleted_flag |
Logical delete flag. Useful for merged patients. Valid values are 1 = yes, deleted; 0 = no, not deleted |
Required |
deceased_flag |
Currently not used. Valid values are: 1 = yes, deceased; or 0 = no, not deceased |
Required |
Many of the columns in the patient table use codes for their values- sex, race, ethnicity, etc. Although these values are not constrained by the database, the UI can display descriptions for them in the patient demographics areas, and are used in the bar charts that breakdown sex, race, gender in the "All Patient Search" feature. The lookup tables for these codes are
-
LKP_PATIENT_RACE
-
LKP_PATIENT_GENDER
-
LKP_PATIENT_SEX
-
LKP_PATIENT_MARITAL_STATUS
-
LKP_PATIENT_RELIGION
-
LKP_PATIENT_ETHNICITY
These tables all have the same structure:
| Column | Description |
|---|---|
DESCRIPTION |
The description that is shown in the User Interface |
CODE |
The coded value in the patient table |
Research Studies and Attestation
Immediately after each login, every user is required to ‘attest’ to their use of EMERSE for that session by specifying their reason for using the system. This is called the ‘Attestation’ page, and the results are stored in the SESSION_ATTESTATION table. EMERSE provides three options (configurable by a system administrator) for this attestation: (1) a free text box, (2) ‘Quick Buttons’ for choosing pre-selected options that are commonl used (for example, “Quality Improvement”, “Patient Care”, “Infection Control”, etc), and (3) a table of research studies to which a user is associated. Additional tables RESEARCH_STUDY_ATTESTATION, and ATTESTION_OTHER may contain additional information depending on whether the user specifies a research study, or other reasons. The free text option would be used by users when no other attestation choices are reasonable. Additionally, previously used entries from the free text box will appear in the table, along with any IRB-approved studies, for the user’s convenience.
| For our implementation at Michigan Medicine, we pull data on all studies in the IRB system, even if the study/person is not currently a part of EMERSE. This is because the dataset is generally small, and it makes it easier for users to validate their studies if the data are already populated, once the user is given an EMERSE account |
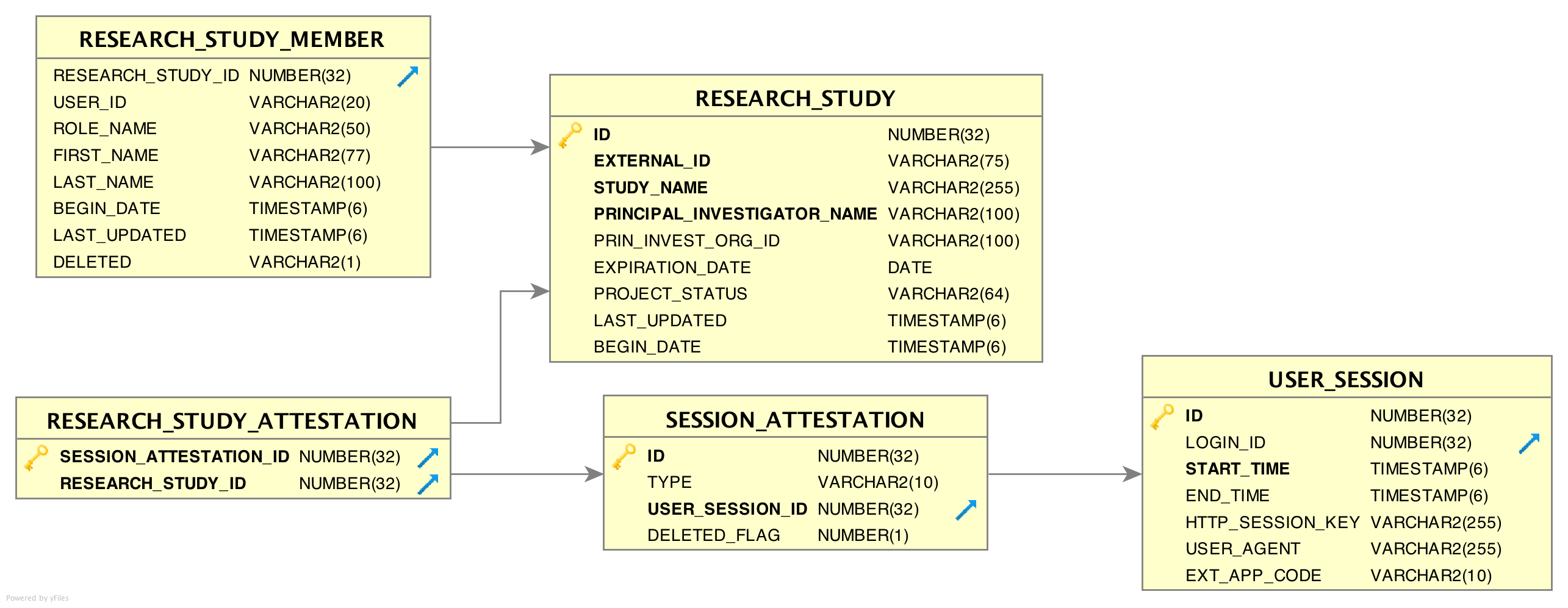
RESEARCH_STUDY table
Table: RESEARCH_STUDY
Population: Populated from external source such as an electronic IRB system
Population Frequency: Can be variable, but once per day is reasonable
| If a user is required to select his/her study from the table, then delays in moving IRB data to EMERSE after IRB approval can result in delays access for that user. |
This table contains information about research studies. Using this table and RESEARCH_STUDY_MEMBER allows EMERSE to show a list of studies the end user is associated with.
| Column name | Description | Required or Optional |
|---|---|---|
id |
Primary Key |
Required |
external_id |
IRB study number — used to link specific studies to usage, and is very helpful for tracking research usage |
Required |
study_name |
Name of the study |
Required |
principal_investigator_name |
Name of the principal investigator |
Required |
prin_invest_org_id |
id of principal investigator. Not currently used by EMERSE. This could be a user id, or email, but it is a good idea to ensure it is unique. |
Optional |
expiration_date |
Expiration date of study. Used to determine if a user should be allowed to proceed. If the expiration date is older than the current date, the user will not be able to select it in the attestion GUI. |
Required |
project_status |
Current project status. This is used to track where a study is in the review and approval process. Only certain study statuses allow access to EMERSE for research. The statuses that allow a study to be selected during attestation are defined in the VALID_RES_STUDY_STATUS table. |
Required |
last_updated |
A last updated date is not used by EMERSE, but can be useful for troubleshooting and tracking changes to the table. |
Optional |
begin_date |
This originally referred to the date the study began or should be allowed to begin. This field that can be used for tracking and troubleshooting. |
Optional |
VALID_RES_STUDY_STATUS table
Table: VALID_RES_STUDY_STATUS
Population: By System Admin. Only needed if research studies need to be validated
Population Frequency: May only need to be done once, at the time of system setup. May need periodic updates if the source data (such as from IRB system) defining study status is changed.
EMERSE contains a simple table defining study statuses. The statuses that are initially populated in the system (loaded up in the build script) are unique to Michigan Medicine (that is, they were developed locally and are implemented in our separate electronic IRB tracking system) and other implementations would have to have their own set of valid statuses if these were to be used to validate and approve usage for research. If the status of a research study is not in this table, EMERSE will not allow the study to be used for attestation; that is, the study would not even be displayed to the user to select.
| Column name | Description | Required or Optional |
|---|---|---|
status |
A list of study statuses that EMERSE considers valid in terms of allowing a user to proceed. These statuses are generally defined by the IRB and are universal across studies. |
Required |
VALID_RES_STUDY_STATUS Table Example:
| Status |
|---|
Exempt Approved - Inital |
Approved |
Not Regulated |
Exempt Approved - Tranistional |
RESEARCH_STUDY_MEMBER table
Table: RESEARCH_STUDY_MEMBER
Population: Populated from external source such as an electronic IRB system
Population Frequency: Can be variable, but once per day is reasonable
This table contains information about study team members, and is related to the RESEARCH_STUDY table, described above. Each study can have one or many study team members.
| This table at Michigan Medicine contains information on all study team members for all studies, whether they have an EMERSE account or not. |
| Column name | Description | Required or Optional |
|---|---|---|
RESEARCH_STUDY_ID |
Foreign key reference to row |
Required |
USER_ID |
Foreign key reference to row in |
Required |
ROLE_NAME |
A string describing a person’s role on the study team. EG. “PI”, “Staff”, “Study Coordinator”. This can be useful when generating usage reports. |
Optional |
FIRST_NAME |
First name of the username who is on the study. It is currently populated from the source IRB system, but it is not used at all by EMERSE. Nevertheless, it may be useful when generating reports. |
Optional |
LAST_NAME |
Last name of the username who is on the study. It is currently populated from the source IRB system, but it is not used at all by EMERSE. Nevertheless, it may be useful when generating reports. |
Optional |
BEGIN_DATE |
This is not currently used by EMERSE. |
Optional |
LAST_UPDATED |
Date row was last updated |
Optional |
DELETED |
Flag to indicate if the record has been logically deleted. 0 = false, not deleted; 1 = true, deleted. |
Required |
SESSION_ATTESTATION table
Table: SESSION_ATTESTATION
Population: Used internally by EMERSE
Population Frequency: In real time by EMERSE
Each time a user attests to why they are using EMERSE, a row is inserted into this table, which is one of the audit tables. Attestations related to research can be joined to the RESEARCH_ATTESTION table. Non research uses can be joined to ATTESTION_OTHER.
| Column name | Description | Required or Optional |
|---|---|---|
id |
Primary Key |
N/A (populated internally by EMERSE) |
type |
A string indicating the top level category of attestation. |
N/A (populated internally by EMERSE) |
User_session_id |
A foreign key reference to the |
N/A (populated internally by EMERSE) |
OTHER_ATTESTATION_REASON table
Table: OTHER_ATTESTATION_REASON
Population: By System Admin. Only needed if commonly used text reasons are needed as quick buttons in the application
Population Frequency: May only need to be done once, at the time of system setup.
For non-research attestations, there is a lookup table called OTHER_ATTESTATION_REASON that lists available options. These can be configured by each institution, and may include commonly used access reasons that don’t involve research (such as quality improvement, patient care, etc). These options (other than the Free text reason) can be used to populate “quick buttons” that provide a simple way for a user to click on one of the common reasons for use.
| Column name | Description | Required or Optional |
|---|---|---|
USER_KEY |
Text based primary key of this table. The column name might better be thought of as as 'reason key'. |
Required |
DESCRIPTION |
The text description that will be displayed in the Quick Buttons section of the Attestation page. |
Required |
DELETED FLAG |
Has this reason been deleted? (0 = no; 1= yes) |
Required |
DISPLAY_ORDER |
Order of display in the UI. Can be any integer, but should be unique per row. The buttons are ordered by this column via sql sort. Generally start with 0,1,2, etc. |
Optional |
OTHER_ATTESTATION_REASON Table Example:
| USER_KEY | DESCRIPTION | DELETED_FLAG | DISPLAY_ORDER |
|---|---|---|---|
QI |
Quality Improvement |
0 |
0 |
RVPREPRES |
Review Preparatory to Research |
0 |
1 |
STDYDESC |
Study involving only decedents (deceased patients) |
0 |
2 |
ATTESTATION_OTHER table
Table: ATTESTATION_OTHER
Population: Used internally by EMERSE
Population Frequency: Application dependent
The free text reasons that users enter are stored in a table called ATTESTATION_OTHER. This is populated by EMERSE and is not customizable by users.
| Column name | Description | Required or Optional |
|---|---|---|
SESSION_ATTESTATION_ID |
A unique ID for the session attestation. Used for audit logging. |
Required |
FREE_TEXT_REASON |
The free text reason that a user entered. |
Required |
OTHER_ATTEST_REASON_KEY |
This will currently only be populated by the system with |
Required |
ATTESTATION_OTHER Table Example:
| SESSION_ATTESTATION_ID | FREE_TEXT_REASON | OTHER_ATTEST_REASON_KEY |
|---|---|---|
50208 |
Testing out the system |
FRETXT |
52060 |
Testing out the system |
FRETXT |
46051 |
Looking up a patient in clinic |
FRETXT |
71052 |
infection control monitoring |
FRETXT |
74107 |
cancer registry operational work |
FRETXT |
Clinical Documents
EMERSE search is enabled by the indexing of clinical text documents by Apache Solr. Documents in a clinical environment can come from a myriad of sources like transcription, Radiology, and Pathology, or from an electronic health record. Normally the structure, data, and metadata related to these documents from different sources varies considerably. To simplify things, we configure Solr with a single document schema containing a congolmerate of all fields from all sources. Common data elements, such as patient MRN, clinical date, and source primary key are used across many sources thus are mapped to the same Solr schema field. Search results for each source are displayed in a separate tab in the UI.
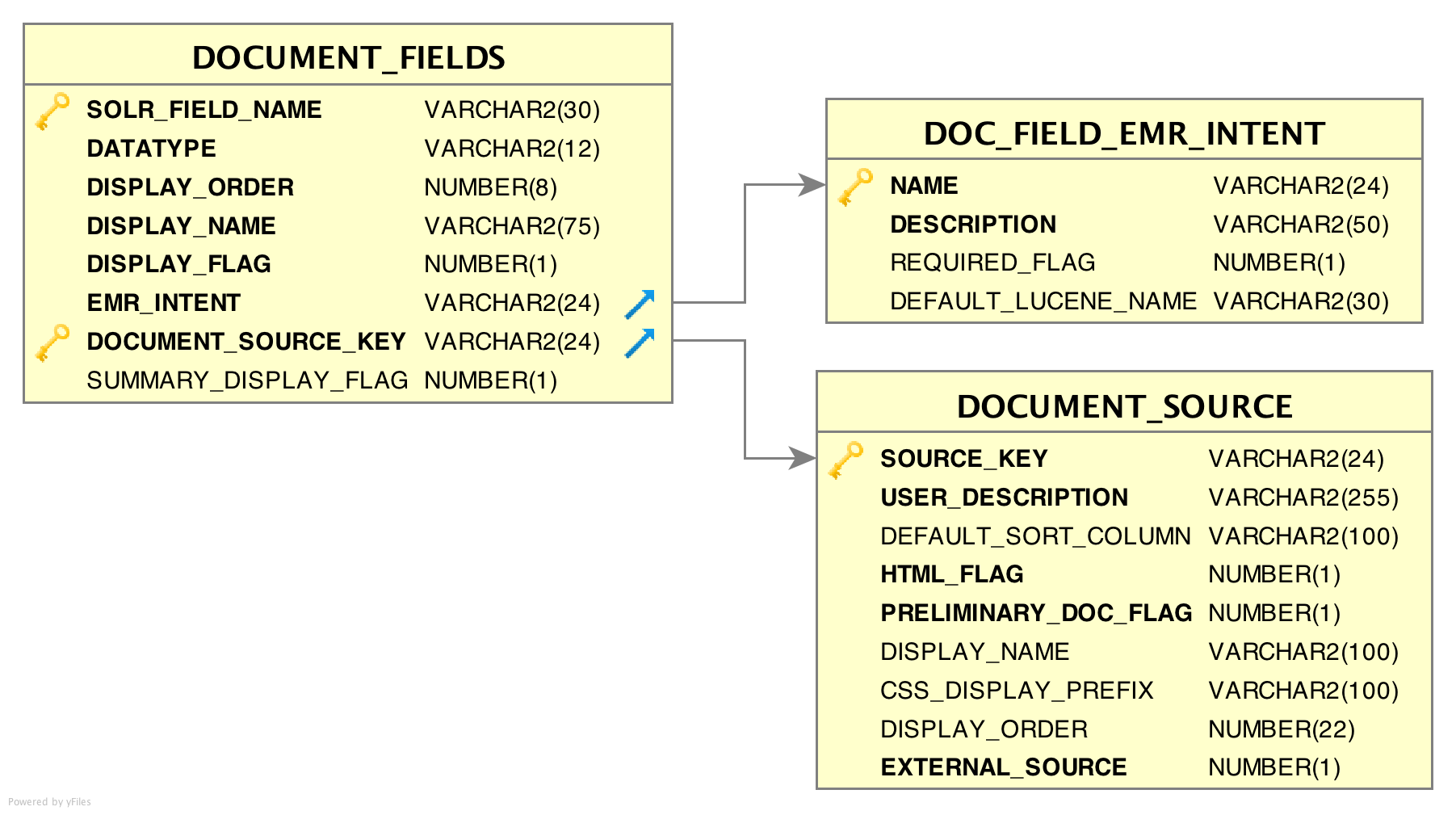
DOCUMENT_INDEX table
Table: DOCUMENT_INDEX
Population: Likely once at system setup
Population Frequency: May need updating as data sources change.
Each source of documents (e.g., pathology, radiology, commercial EHR, legacy EHR, etc.) is listed as a row in the document_index table. The EMERSE application searches and displays the results based on document source. Additionally, Advanced Search Queries within EMERSE can leverage these source data to limit queries to a specific source (e.g., searching only pathology reports). Document sources normally differ in their format and metadata depending on the source of origin. Each row in this table corresponds to a column in the “Overview” display within EMERSE, and as a subset of documents when a patient is selected.
| Column name | Description | Required or Optional |
|---|---|---|
lucene_name |
Name of the document source. This field needs to be unique and search results are displayed on separate tabs for each source. However, this name is not displayed to the user but instead is used to match the name of the document source as defined in the Solr configuration, in the |
Required |
user_description |
Description for the source of document. This field is used only internally and can be useful for system admins who set up EMERSE to provide a a description of the lucene_name for easier recognition. This is not displayed to users in the UI. |
Required |
compound_key_flag |
This flag is present for historic reasons and will be deprecated in future releases.
Note:
Lucene indexing requires that each document has a unique identifier. So, when indexing, the fields that uniquely identify a document need to be concatenated and indexed as |
Required |
display_name |
The name displayed in the UI |
Required |
display_prefix |
Prefix used by internally by CSS components in the UI. This can be anything, but each source must have a unique |
Required |
display_order |
Order in which sources appear in the Overview and the tabs within the Summary results page. Each row should have a distinct display order. Start sequential number with 0. |
Required |
DOCUMENT_INDEX Table Example:
| lucene_name | user_description | compound_key_flag | default_sort_column | display_name | display_prefix | display_order |
|---|---|---|---|---|---|---|
DMI |
Central transcription document |
0 |
Case Date |
CareWeb |
dmi |
0 |
Radiology |
Radiology Documents |
0 |
Report Date |
Radiology |
rad |
1 |
Pathology |
Pathology Document |
0 |
Last Updated |
Pathology |
path |
2 |
DOCUMENT_FIELDS table
Table: DOCUMENT_FIELDS
Population: Likely once at system setup
Population Frequency: May need updating as data sources change.
This table provides EMERSE with information about what fields are available in the underlying Solr/Lucene index, their data type, and additional metadata. Each field indexed with Solr/Lucene should exist in this table for each source system in the document_index table. The column EMR_INTENT is linked to the name field of the doc_field_emr_intent mapping table. The column DOC_INDEX_LUC_NAME is linked to the lucene_name field of the document_index table.
Each document source should contain at least six rows (see ‘EMR Intent’ and the doc_field_emr_intent table below for the six required types). One for each type as defined in document fields table. Additional fields can be specified using the generic EMR_INTENT options of TEXT or DATE. These additional/optional metadata fields are used by EMERSE for display in the UI but are not used by Solr/Lucene. Also, note that indexing of these fields depends on the Solr configuration which must define these fields for indexing.
| Column name | Description | Required or Optional |
|---|---|---|
LUCENE_NAME |
Name that corresponds with the Solr document field . The names of the fields are specified in |
Required |
DATATYPE |
Mainly used by the UI Should be either “Text” or “Date” (case-sensitive) |
Required |
DISPLAY_ORDER |
Order in which fields need to appear in the search results |
Required |
DISPLAY_NAME |
Name that appears in the UI |
Required |
EMR_INTENT |
Specifies the intent of the field. This refers to the fields defined in the |
Required |
DOC_INDEX_LUC_NAME |
Specifies the document type key from |
Required |
DISPLAY_FLAG |
Flag that controls if the field is displayed when document is displayed. This display of metadata is in a small table above the document when an individual document is shown in the EMERSE UI. (1 = yes, display; 0 = no, do not display) |
Required |
SUMMARY_DISPLAY_FLAG |
Flag that controls if the field is displayed in search results summary page, which would show up as a metadata coulumn in the Summary results table. (1 = yes, display; 0 = no, do not display) |
Required |
DOCUMENT_FIELDS Table Example:
Shown below is an example document_fields table for three different document sources:
| LUCENE_NAME | DATATYPE | DISPLAY_ORDER | DISPLAY_NAME | EMR_INTENT | DOC_INDEX_LUC_NAME | DISPLAY_FLAG | SUMMARY_DISPLAY_FLAG |
|---|---|---|---|---|---|---|---|
MRN |
Text |
0 |
MRN |
MRN |
DMI |
0 |
0 |
RPT_TEXT |
Text |
1 |
Report Text |
RPT_TEXT |
DMI |
0 |
0 |
RPT_TEXT_NOIC |
Text |
2 |
Report Text |
RPT_TEXT_NOIC |
DMI |
0 |
0 |
ID |
Text |
3 |
Report ID |
RPT_ID |
DMI |
1 |
1 |
LAST_UPDATED |
Date |
4 |
Last Updated |
LAST_UPDATED |
DMI |
1 |
0 |
CASE_DATE |
Date |
5 |
Case Date |
CLINICAL_DATE |
DMI |
1 |
1 |
MRN |
Text |
0 |
MRN |
MRN |
PATHOLOGY |
0 |
0 |
RPT_TEXT |
Text |
1 |
Report Text |
RPT_TEXT |
PATHOLOGY |
0 |
0 |
RPT_TEXT_NOIC |
Text |
2 |
Report Text |
RPT_TEXT_NOIC |
PATHOLOGY |
0 |
0 |
ID |
Text |
3 |
Report Id |
RPT_ID |
PATHOLOGY |
1 |
1 |
LAST_UPDATED |
Date |
4 |
Last Updated |
LAST_UPDATED |
PATHOLOGY |
1 |
1 |
DR_NUM |
Text |
5 |
Doctor Num |
TEXT |
PATHOLOGY |
1 |
1 |
COLLECTION_DATE |
Date |
6 |
Collection Date |
CLINICAL_DATE |
PATHOLOGY |
1 |
0 |
MRN |
Text |
0 |
MRN |
MRN |
RADIOLOGY |
0 |
0 |
RPT_TEXT |
Text |
1 |
Report Text |
RPT_TEXT |
RADIOLOGY |
0 |
0 |
RPT_TEXT_NOIC |
Text |
2 |
Report Text |
RPT_TEXT_NOIC |
RADIOLOGY |
0 |
0 |
ID |
Text |
3 |
Report ID |
RPT_ID |
RADIOLOGY |
1 |
1 |
LAST_UPDATED |
Date |
4 |
Last Updated |
LAST_UPDATED |
RADIOLOGY |
1 |
0 |
SVC_CD |
Text |
5 |
Service Code |
TEXT |
RADIOLOGY |
1 |
0 |
DR_NUM |
Text |
6 |
Doctor Num |
TEXT |
RADIOLOGY |
1 |
0 |
RPT_DATE |
Date |
7 |
Report Date |
CLINICAL_DATE |
RADIOLOGY |
1 |
1 |
DOC_FIELD_EMR_INTENT table
Table: DOC_FIELD_EMR_INTENT
Population: Likely once at system setup
Population Frequency: May need updating as data sources change.
This is a lookup table for the column EMR_INTENT in the previously defined document_fields table. This table does not normally need to be edited. It is used by the system to help map various sources and types of data to the intended uses of those data by the system. The values contained in the name field of this table are listed below.
| DOC_FIELD_EMR_INTENT is used internally by EMERSE. The first 6 items are required for the Solr/Lucene indexer to work, the next two are optional, and the final one is no longer used. |
| Column name | Description | DEFAULT_LUCENE_NAME | Required or Optional |
|---|---|---|---|
MRN |
Patient medical record number, which is a unique patient identifier |
MRN |
Required |
RPT_ID |
Unique document identifier. This must be unique across all documents and sources |
ID |
Required |
CLINICAL_DATE |
Date when the clinical event occurred. Often this would be considered the “note date” |
ENCOUNTER_DATE |
Required |
LAST_UPDATED |
Date when the document was last updated, since changes are sometimes made to documents |
LAST_UPDATED |
Required |
RPT_TEXT |
The actual text of the clinical document. This field is used by Lucene for lower-case indexing (case-insensitive searching). |
RPT_TEXT |
Required |
RPT_TEXT_NOIC |
A copy of the document text to be indexed using a case-sensitive Lucene filter (NOIC = NO Ignore Case) |
RPT_TEXT_NOIC |
Required |
TEXT |
Any generic text field. Note that a document may have multiple of these types of generic text fields (e.g., clinical service, document type, clinician name, etc). This is useful when additional metadata are associated with the document and should be displayed. If this field is also defined in the Solr configuration it can become searchable. Otherwise, it could still potentially be used to help filter queries based on additional metadata (e.g., 'study type'). |
Optional |
|
DATE |
Any generic date field, since a document may have more than one kind of date associated with it. Otherwise, it could still potentially be used to help filter queries based on additional metadata |
Optional |
|
ENCOUNTER_ID |
This is no longer used. It had been used for a time to search across all patients without limiting it to a set of medical record numbers. |
No longer used |
LUCENE_SHARDS table
Table: LUCENE_SHARDS
Population: Likely once at system setup, but the dates may get updated with every indexing.
Population Frequency: Variable, but usually automated.
EMERSE previously used this table to locate Solr/Lucene indexes that were available, as several indexes (shards) were created to improve performance. However, we no longer user multiple indexes. For most users running EMERSE on a single server, having one row in this table pointing to a single Solr/Lucene index yields adequate performance for 1-2TB indexes with 100’s of millions of documents. Thus, only one index needs to be defined here. After indexing, EMERSE will automatically update the START_DATETIME and END_DATETIME fields with the latest date range of the indexed documents. The Start and End dates in this table are used within the EMERSE UI to display the date range of the documents. The automatic updating of the start and end dates can be overriden using two parameters (see batch.updateIndexMinDateFromSolrIndex and batch.updateIndexMaxDateFromSolrIndex in the 'Batch Updating' section of the Configuration Guide).
| If the need arose to break the index into smaller pieces for performance gains, we would recommend using Solr Cloud instead. |
| Column name | Description | Required or Optional |
|---|---|---|
ID |
The Lucene name of the index |
Required |
PARENT_DOC_INDEX |
Specifies the document type key from document_index table. This used to refer to a specific shard. |
Optional (Needed when using multiple shards) |
START_DATETIME |
Start date of clinical documents in this shard |
Required |
END_DATETIME |
End date of clinical documents in this shard |
Required |
LUCENE_SHARDS Table Example:
| ID | PARENT_DOC_INDEX | START_DATETIME | END_DATETIME |
|---|---|---|---|
unified |
(null) |
01.02.2008 00:00:00 |
31.12.2099 00:00:00 |