
Overview
This guide provides information on integrating external data into the EMERSE application, as well as basics about the indexing process. In order for EMERSE to search and highlight documents, they must be submitted to the Solr instance to which EMERSE is attached. Additionally, patients who have indexed documents need their corresponding demographics to exist in EMERSE’s Patient table. Optionally, research study and personnel (user) information can be loaded into a few EMERSE tables that will allow EMERSE to check that authenticated users are research personnel for approved studies, which is used for determining research access and populating the audit tables at the time of login.
Data integration and indexing are tightly linked, which is why they are discussed together in this guide. Not covered in depth is Solr itself, as this is already well documented elsewhere. Note that knowledge of Solr will be crucial to indexing for EMERSE.
Integrating Documents
The EMERSE application uses Solr to search, highlight, and display documents. This section provides possible approaches for submitting documents to Solr for indexing, as well as information about conforming your documents to the Solr schema that EMERSE requires.
Document Metadata / Solr Schema
Each Solr index uses an XML configuration file (managedschema.xml) that describes the fields that exist for the documents that will be indexed. This file informs Solr of the datatypes of the fields (String, Date, etc), but is also used to configure numerous settings related to how documents are analyzed (tokenized). The EMERSE software is tightly coupled with a specific Solr Schema.
EMERSE Solr schema
An excerpt from the Solr configuration file is shown below. It shows the required fields needed for EMERSE to function. Each document needs at least four metadata fields (MRN, RPT_ID, RPT_DATE, SOURCE) as well as the document text, stored in RPT_TEXT. Other fields can be added, but the three listed above are the minimum needed for EMERSE to function properly.
<field name="MRN" type="string" indexed="true" stored="true" />
<field name="RPT_ID" type="string" indexed="true" stored="true" />
<field name="RPT_DATE" type="date" indexed="true" stored="true" />
<field name="SOURCE" type="string" docValues="true" indexed="true" stored="true"/>
<field name="RPT_TEXT" type="text_general_htmlstrip" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />
<field name="RPT_TEXT_NOIC" type="text_general_htmlstrip_nolowercase" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />
<field name="_version_" type="long" indexed="true" stored="true"/>Required fields:
-
RPT_ID- This should hold a unique identifier for a document. When indexing from multiple sources, make sure that keys don’t overlap. At Michigan Medicine we prefix the source systems' primary key to ensure uniqueness between systems. -
MRN- The unique identifier for the patient associated with the document, usually the medical record number. -
RPT_DATE- A date for the document, usually the creation date or date of service. Used in the UI to sort and limit results. -
RPT_TEXT- The actual text of the note or document. This will ultimately be lower-cased and indexed for case-insensitive searches (the default). -
RPT_TEXT_NOIC- This field is automatically copied from RPT_TEXT. It should not be submitted with indexed documents. It is used to create a copy of the document text that is case sensitive. This case-sensitive version is used in a separate index for searching terms in a case-sensitive manner.
Optional fields:
Additional metadata, such as a document type (e.g., “progress note”, “surgical note”) and clinical service (e.g., “general pediatrics”, “rheumatology”), can also be included. These are helpful for users, as they can be displayed when the application displays lists of documents. Additionally they may be used to sort documents and for filtering results.
Each field in the Solr schema needs to also exist in the database table DOCUMENT_FIELDS. Each field should have an associated row in this table. The application uses the database information to provide the UI with additional information about each field that can’t be added to the Solr configuration. See the Data Guide for more information.
|
_version_ is not a field that we modify for EMERSE, but it must remain because it is required by the Solr schema.
|
Technical approaches for Solr indexing
Getting documents from source systems will vary considerably at each site and will depend on multiple factors including the number of different sources, how the documents are stored, how they are formatted, the type of access or connections available, etc.
Three high level approaches are briefly described here, with details in additional sections that follow:
-
Custom code with Solr Client: We have found this to be the ideal approach because of it’s speed, multi-threaded capabilities, and flexibility. Client libraries are available for most common programming languages. [solr-details]
-
Solr Data Import Handler (DIH): The Solr DIH ships with Solr and is relatively easy to use. It may be a good approach for getting started and learning Solr. However, while the DIH is useful to understand how the retrieval/indexing process works, the DIH is slow compared to other methods and is not multi-threaded so we do not recommend it for large-scale implementations. See: Indexing using Solr DIH (Data Import Handler)
-
Data integration/ETL tools: Documents can also be presented to Solr using non-developer tools such as Pentaho Data Integration (PDI), which is free and open source, and is used on our demonstration EMERSE Virtual Machine for loading/indexing data. [pdi-details]
Indexing programmatically with Solr Client
Our primary tool for working with Solr at Michigan Medicine has primarily been with SolrJ, a Java based client used to add/update documents in a Solr index. The remainder of this section references SolrJ, but is applicable to Solr clients in other languages.
There are Solr API’s/ Clients available for different programming languages should Java be less desired. This page provides numerous links to other language implementations:
At the University of Michigan we have developed a small amount of custom code to sit between our various source systems and Solr. This custom code is not part of the standard EMERSE release since the specific needs will vary for each institution. The code pulls data from our document repositories via SQL/JDBC and presents the documents to Solr for indexing via SolrJ. This approach also allows us to do additional transformations as needed such as converting documents in RTF format to HTML format which is ideal for displaying in EMERSE. Another possible type of transformation is concatenating pieces of a document from multiple database rows. This can be done through SQL or through custom code, but it needs to be done before presenting the document to Solr for indexing.
We are using Unix Cron to schedule a simple curl HTTP request to be made to the indexing code to start once per night. By using modification time information available in the source systems, and remembering the last time indexing occurred, we are able to index only documents changed since the last time the indexing jobs have run.
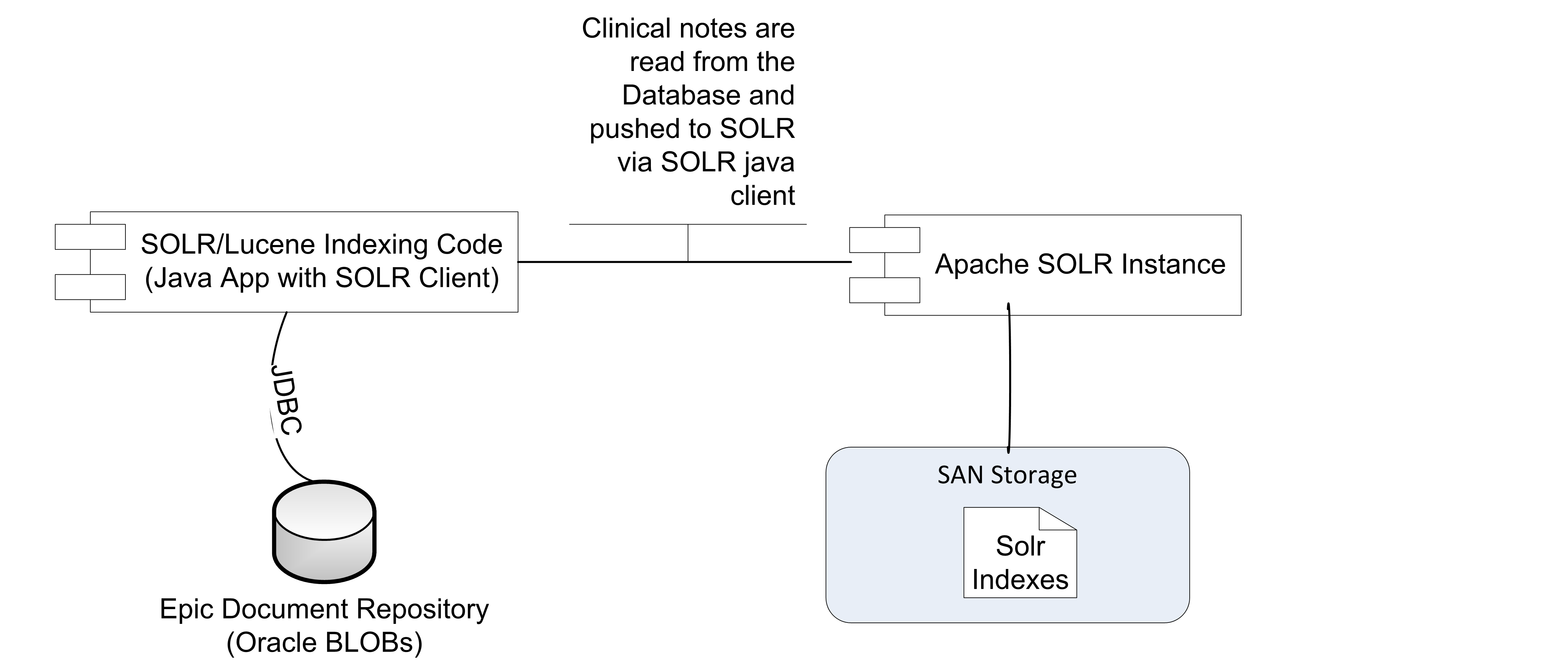
| To get started programming with the SolrJ API http://www.solrtutorial.com/solrj-tutorial.html |
Indexing using Solr DIH (Data Import Handler)
Probably the easiest way to get started with document indexing is to use the Solr Data Import Handler (DIH). This comes packaged with Solr and is easy to get up and running. While the DIH is useful to understand how the indexing process works, the DIH is slow compared to other methods and is not multi-threaded so we do not recommend it for large-scale implementations. The DIH can be configured to access a source system or database, with details about how to retrieve and potentially ‘transform’ the document constructed in SQL. For example, some documents may be in a database with a single document split across multiple rows. The document can be re-assembled into a single text field using SQL and then Solr can process it. Note that Solr expects a document to be ‘pre-assembled’ and does not itself concatenate fields to reconstruct a document from pieces, which is why this should be done in the SQL that retrieves the document. With the DIH you can define the query and the target source in its associated configuration file, and it will pull documents from that source and present them to Solr for indexing.
|
Reference: https://lucene.apache.org/solr/guide/6_6/uploading-structured-data-store-data-with-the-data-import-handler.html Reference: https://wiki.apache.org/solr/DataImportHandler |
Getting started with DIH:
The main steps in using DIH are:
-
Enable DIH in solr config (see below)
-
Create an xml that will instruct SOLR how to access documents
-
Install the JDBC driver and configure datasource
-
Data Import Handler has to be configured in the
solrconfig.xml(located insolr.homedirectory) Uncomment the lines below insolrconfig.xmlto make them active.
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">dataconfig.xml</str>
</lst>
</requestHandler>-
Database configuration information and the queries needed to retrieve documents are specified in DIH
dataconfig.xmlfile. A sample configuration with mandatory fields required by EMERSE is shown below.
<dataConfig>
<dataSource name="XE" driver="oracle.jdbc.driver.OracleDriver" url="jdbc:oracle:thin:@localhost:1521:XE"
user="system" password="abc" /> +
<document name="rpta">
<entity name="rptsa" pk="RPT_ID" query="select report_id,medical_record_num,cast(report_date as date) report_date,report_text, cast(clinic_date as date) clinic_date from emerse.reports_ctsa where rpt_type=1"
transformer="ClobTransformer,DateFormatTransformer">
<field column="report_id" name="RPT_ID" />
<field column="report_text" name="RPT_TEXT" clob="true"/>
<field column="medical_record_num" name="MRN" />
<field column="report_date" name="RPT_DATE" dateTimeFormat="yyyy-MM-dd HH:mm:ss.S" locale="en" />
<field column="clinic_date" name="CLINIC_DATE" dateTimeFormat="yyyy-MM-dd HH:mm:ss.S" locale="en"/>
</entity>
</document>
</dataConfig>-
A java based driver for the database (JDBC driver) should be installed in the Solr instance in the directory
SOLR_HOME/server/lib. The first element indataconfig.xmlis the dataSource. The JDBC URL in the previous snippet is using Oracle. Other database types will require a different driver name.
The DIH can be run from the Solr web application. It is accessible under Core Admin/DataImport menu option. DIH commands can also be directly sent to Solr via an HTTP request. For example, the command to start a full-import is:
Indexing with ETL tools
Documents can be pushed to Solr in a number of ways. The Solr project provides a native Java API, a REST API that can be invoked via ETL tools, curl, or other simple HTTP utilities. At Michigan Medicine, we primarily use the Java API to index documents, but have also successfully used other ETL tools such as Pentaho Data Integrator (PDI).
| PDI is currently used to load/index data on our Virtual Machine (VM) distribution of EMERSE. |
Many possible implementations of PDI jobs could help with indexing documents, but one scenario we have experimented with is where PDI reads a database and for each row does a HTTP POST call to Solr with the document and metadata in a JSON type of structure.
| When using PDI HTTP connectors, consider sending large batches of documents. This will prevent having to open a connection for each document. For further performance improvement, consider enable partitioning in transforms, so that multiple threads are enabled for at least the HTTP portion of this type of PDI job. http://wiki.pentaho.com/display/EAI/Partitioning+data+with+PDI |
About Solr
Updates and Solr Documents
Solr determines if a document should be added versus updated/replaced based on a unique document key. If you send Solr a document with a previously used key, Solr will replace the older version of the document with the newer version, but the document will still exist, flagged as replaced, in the index files. This may be needed in cases where the document was updated (e.g., addended) or even where the metadata has changed (e.g., the document was previously assigned to the wrong patient MRN). Over time, Solr may contain numerous deleted documents that can degrade performance. Solr provides an Optimize command to rewrite the indexes to remove these. For more information see Solr Optimization in the EMERSE Configuration/Optimization guide.
Indexing with the Epic EHR
Many academic medical centers use the Epic EHR. There are multiple ways in which to get documents out of Epic, each with its own advantages and disadvantages. Several of these options are described below. Regardless of how the documents are extracted, we recommend storing documents extracted from the EHR in a document repository, and it would be from this interim repository that documents would be pushed to Solr for indexing. Such a repository is not needed at run time for EMERSE, since EMERSE stores its own local copy of the documents (thus there are no real-time calls to Epic when EMERSE is running). Nevertheless, having a document repository will be important if, for example, it becomes necessary to rebuild the indexes, or possibly for comparing existing notes within EMERSE to any new notes that have been generated by the EHR.
| Images or drawings within a document are not incorporated into the Solr indexing process and thus cannot be viewed within EMERSE. It is theoretically possible to save the images elsewhere and create hyperlinks back to the images if needed. |
Regardless of what approach is used for extracting notes, it may be worth concatenating other data to the note to make a larger, more comprehensive, and self-contained note detailing additional aspects of the patient encounter. For example, if a clinical note from an encounters is extracted, it is possible through other queries to extract a medication list at the time of the encounter, append it to the note, and then store this larger, concatenated merged document in a document repository. Such additional data may be useful for users.
-
HL7 Interface: The current way in which EMERSE at Michican Medicine receives encounter summaries and notes from Epic is via an Epic Bridges outbound HL7 interface. Details about this interface can be found here:
There may be a fee required by Epic to turn on this interface. The emitted HL7 messages include a report, which includes the clinical note as well as other structured data from an encounter in RTF format, which (importantly) preserves the formatting and structure of the notes. The reports are highly configurable by combining Epic print groups, which dictate the content of the report/RTF file. This can make searching more comprehensive for users. The RTF files obtained via this interface are converted to HTML by the commercial software Aspose.Words API, and stored in our document repository for nightly indexing by Solr.
Information on Aspose can be found at http://www.aspose.com/java/word-component.aspx Available metadata in the HL7 message, such as
Encounter Date,Department, andEdit Date, are also stored in the repository along with the note. We recommend that you try to only include finalized, or ‘signed’ notes in the repository to prevent the need to continually monitor for document changes and frequent re-processing and re-indexing. However, such decisions will need to be made locally depending on the local use cases, and needs/expectations of users.One disadvantage of this approach is that it is not useful for loading/extracting historic documents. That is because this outbound document HL7 interface is triggered to send the document based on pre-specified actions (signing a note, for example) and cannot be called on an ad hoc basis.
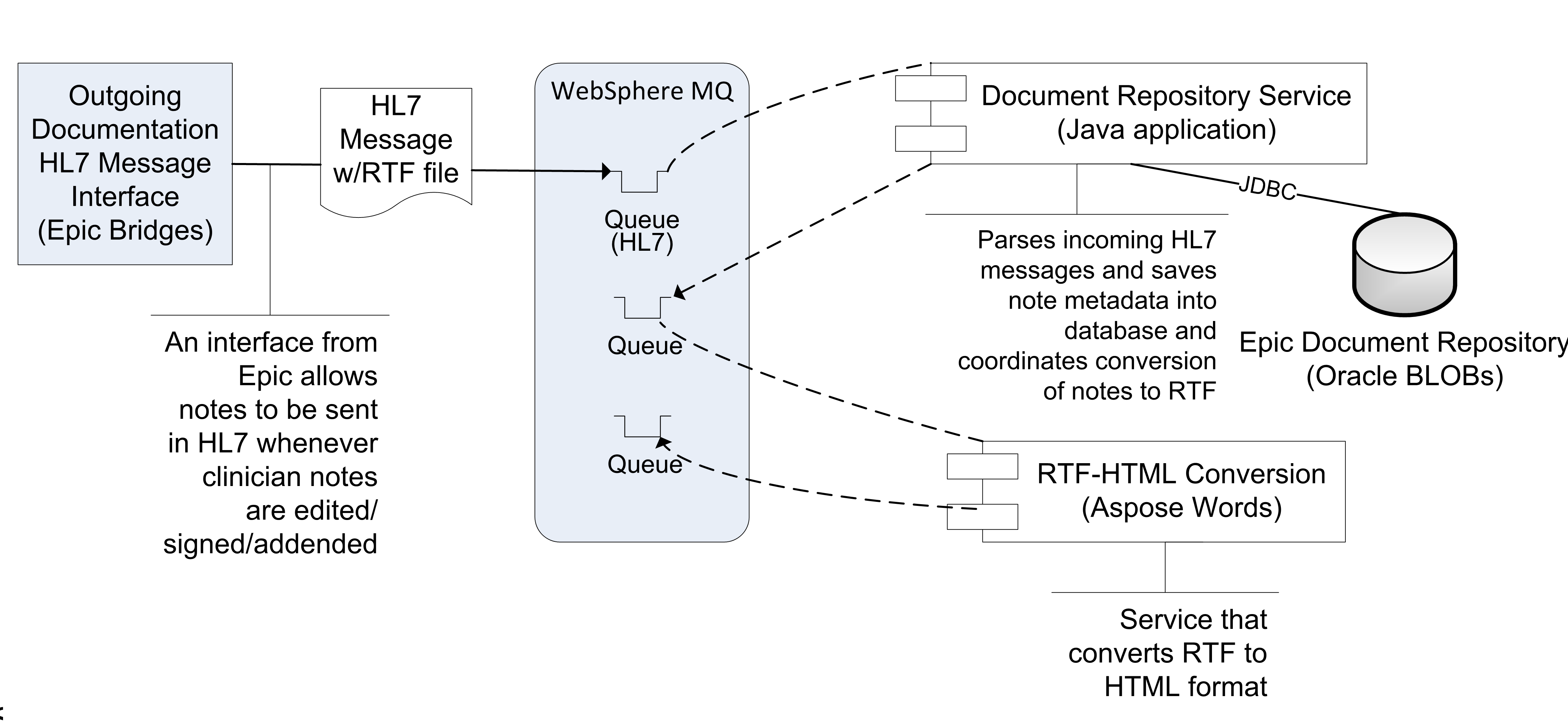 Figure 2. The approach used at the University of Michigan to obtain notes from the Epic EHR and make them searchable within EMERSE.
Figure 2. The approach used at the University of Michigan to obtain notes from the Epic EHR and make them searchable within EMERSE.
-
Epic Clarity: It is also possible to receive notes through the Epic Clarity database; however, at the time of this writing Clarity strips some document formatting, and thus display of the notes will not look as they appear in Epic. The original document formatting may be essential for understanding/interpreting the document once displayed within EMERSE, including the structure of tables, and other common markup such as bolding, italics, etc. Epic Clarity currently does preserve some formatting such as line breaks, but doesn’t include tables and other text formatting. This may depend on the configuration of the ETL jobs that populate Clarity.
If there is a desire to use Clarity to obtain notes, we suggest looking into the following tables:
HNO_INFO (note metadata) HNO_ENC_INFO (notes /encounter linkage) HNO_NOTE_TEXT (actual note text)These tables don’t seem to be documented in Epic’s Clarity ambulatory care documentation, even though outpatient notes are stored in the same tables along with the inpatient notes as of Epic 2015. However, The inpatient Clarity “training companion” does have an overview of these tables, and they are mentioned in the Clarity data dictionary, so between these two references you should be able to build a query that collects Epic notes.
Clarity might still be useful in order to keep track of what documents have been changed (for example, a note might be deleted or addended weeks after it has been stored and indexed in EMERSE).
-
Epic Web Services: It is possible to build a web service to extract documents that preserves the original formatting of the notes.
At the University of Michigan we have built a custom web service that extracts formatted notes directly from Chronicles (not Clarity). These notes still have their native formatting which is in RTF, but they are converted to HTML and embedded in a SOAP message during the web service call. This approach will require individuals to have experience with writing custom web services and Epic Cache code. Those interested in exploring this option can contact us at the University of Michigan and we can share the Cache code and the web service definition.
With Epic’s support of the FHIR standard, it is possible that future Epic releases may have a webservice to pull documents "out of the box" Epic’s webservices are not used for EMERSE at Michican Medicine, but are being used elsewhere in our health system. The major challenge with using the webservices is that they require knowledge of the primary note identifier before making the webservice call. It should be possible, however, to use clarity to pull note identifiers and then make a webservice call to retrieve the note as RTF/html.
| Depending on the integration approach, it may be useful to setup a staging database that sits between the source systems and the EMERSE Solr indexes. The primary use of this at Michigan Medicine is to store the documents as they are received from Epic as HL7 messages. They are not directly stored in Solr, even though Solr ultimately creates its own local copy once a documents is sent from the staging database to Solr. |
Patient Integration
EMERSE requires that all patients referenced in documents exist in the Patient database table. At the University of Michigan, the Patient table is updated once per day (overnight) which coincides with the timing of indexing all new/changed notes (also once per day). The Solr indexing process does not require that this table be up to date, but the EMERSE system will need the MRNs to match between the PATIENT table and the Solr indexes for everything to work properly when users are on EMERSE.
Research Study Integration
EMERSE is often used to aid in research studies. While not required, there is a provision for users conducting research to select a research study they are associated with at the "Attestation Page" after successfully logging in. EMERSE then links that particular session with the study in the EMERSE audit logs. Loading your institutional IRB data into the research tables in EMERSE will enable it to show the studies that each user is associated with, that are not expired, and that have a valid status (e.g., Approved status).
At the University of Michigan we use a commercial IRB tracking system (Click Commerce). A subset of the data from this system are moved to a data warehouse every night, and we extract a subset of data from that warehouse to bring into EMERSE for validation of users to studies. A Pentaho Data Integrator job, external to EMERSE, copies this subset to the research study tables in EMERSE, nightly.
| If there are large delays in updating the RESEARCH_STUDY tables, it can delay users access to EMERSE, since the study will not appear in the attestation screen for the user to select. There is also a chance that a user could still be permitted to be approved for use on a study even if the study was revoked (again because of the delay introduced by nightly refreshes). |
LDAP integration
EMERSE can be configured to use LDAP for user authentication. At this time, however, EMERSE authorization can not be done exclusively with LDAP - only users in the LOGIN_ACCOUNT table can access EMERSE even when LDAP is enabled. This was done intentionally so that accounts could be provisioned/revoked on a manual basis, pending review. The configuration guide provides details on changing settings that will enable LDAP authentication.