
Overview
This guide provides a general overview of the components needed to run EMERSE, how to install them, and how to verify that they are running. The guide covers step-by-step directions on how to install everything on a linux server.
For this guide we provide three already created Solr indexes to use as well as SQL scripts to create the database schema and populate it with sample data. An actual production instance would require the creation of the Solr indexes, populating the patient table, and additional localized configurations dependent on document sources and metadata. Nevertheless, this guide should provide enough detail to understand how everything is installed and provides the ability to test the final installation to ensure that it is functional.
If you run into trouble, we recommend that issues get posted to our Discourse Message Forum so that they can be available to all of our developers as well as the larger EMERSE community. The forum is also a good place to search for issues that may have already been addressed.
Supported Operating Systems
EMERSE is mainly tested on enterprise Linux systems (RHEL and SUSE), so we recommend these or their open source equivalents. Windows based platforms should work as well, provided they are recent enough to have quality Java releases, as EMERSE and most of the components run within a Java Virtual Machine.
Planning
Personnel
To install EMERSE, someone with sys admin skills is desirable. This person should be able to install and configure software, edit database tables, etc. No actual programmer experience is needed for a default installation and configuration of EMERSE. Knowledge of servers, Java, Linux, and Apache software will be useful skills for this installation.
Timelines
The initial setup described in this guide can probably be done in a day or less. More time will be required for additional customizations and planning related to localized needs, document extraction and indexing, regulatory approval, etc.
Server and Storage
A Linux/Unix based server is suggested for installing the application server and for hosting the indexing services. No specific type of storage is required, but in general the server should be connected to the highest speed storage available. EMERSE performs a lot of disk reads to retrieve the documents, so read performance is important. We have conducted some experiments using SSD storage and have found it to provide nearly a two-fold increase in system performance for EMERSE, most noticeably in the area where all documents are retrieved and highlighted for a pre-defined set of patients.
Storage capacity is dependent on number of documents to be indexed. While no longer our latest statistics, at one point at Michigan Medicine 2.2TB was used to host approximately 166 million documents in both TXT and HTML format on the production server. An additional 4 TB was available for index optimization, as optimization requires about 2x the size of the index. If your documents are heavily formatted (e.g., HTML instead of TXT), storage requirements may be higher.
Database Sizing
EMERSE doesn’t place great demand on the Oracle database, so a relatively small server can be used with 10-50 GB of storage allocated for user tablespaces. While no longer up-to-date, at one point at Michigan Medicine we were using 8 GB of database space for production EMERSE with 600+ users and 5 years of data (audit logs, user settings, etc).
Server setup
For a production install of EMERSE you will probably want to set up a Linux server based on whatever local options are available. For the purposes of this install guide, a desktop Fedora Linux machine was used to carry out the steps.
Component Installation
The remainder of this guide covers the process of installing and configuring the application server where the EMERSE application will be deployed. Specifics for installing each of these components follows.
| For some of the commands shown in this guide, specific version numbers will be shown as examples. Depending on the software component, the version number you download and install may differ from these examples. Make note of these potential differences when executing the instructions on the command line to ensure that they work successfully. |
Also note that most of these directions are directed at a Linux installation, but we have provided some details for Windows for those interested in trying to install EMERSE on a Windows server.
For the purposes of this installation guide, all components will be stored in a directory called /app. In reality it can be any directory, but for consistency they will go here in this guide.
| Name | Version | Description | Download URL |
|---|---|---|---|
Java JDK |
17 |
Java Development Kit/SDK (JDK) |
|
Apache Tomcat |
9.0.65+ |
Java Servlet Engine |
|
Apache Solr |
8.11.2 (or higher, but not a major version higher) |
Indexing/Information Retrieval System |
|
Relational Database |
10.3 or higher |
Many databases work with EMERSE; we will use this MariaDB since it’s easy to install on linux. |
|
EMERSE WAR file |
latest version |
EMERSE Web Archive File (WAR file) deployment and configuration |
https://github.com/project-emerse/emerse/releases/ You must log in to GitHub.com and be grated access to EMERSE, otherwise this page will appear as a 404. |
Java
The first step in installing EMERSE is to download and install a Java Development Kit (JDK) on the server. Java 17 or higher is required because it was compiled under that version.
Operating Systems often include a Java runtime, and is available on the PATH variable. We will use the java available from the linux distribution’s package manager, and install it like so:
sudo dnf install java-17-openjdk
# Confirming installation:
java --versionThe latter command should print out the java version installed, and confirms that Java is on the path.
Apache Tomcat
EMERSE is packaged as a Java based WAR file that will be deployed to the Tomcat Servlet engine. Tomcat depends on a Java JDK. Tomcat version 9 is required. The Tomcat download page lists a number of components available for download. Only the "Core" software is required. See Required Software section.
We’ll navigate to the apache website and click on the "tar.gz" link under the "Core" bullet point. This should download apache from a mirror near you. Then unzip the in the /app directory:
cd /app
tar zxf ~/Downloads/apache-tomcat*.tar.gz
# Let's rename the directory to just "tomcat" for simplicity
mv apache-tomcat* tomcatLet’s start tomcat to confirm it works:
/app/tomcat/bin/catalina.sh startOpen a browser and navigate to http://localhost:8080/. A Tomcat welcome screen should appear.
To stop tomcat, you just need to do:
/app/tomcat/bin/catalina.sh stop(Though you don’t need to do that now.)
Apache Solr
EMERSE leverages Apache Solr for searching documents. See Required Software section for the specific version to use. The Solr version should have the same major version as specified, and a minimum of the minor version. Otherwise, the sample indexes provided may not be usable, and EMERSE may not function.
Navigate your browser to https://solr.apache.org/downloads.html and download the latest .tgz BINARY release of Solr. We’ll expand it under /app and rename it, just like tomcat:
cd /app
tar zxf ~/Downloads/solr*.tgz
mv solr* solrLet’s start solr to confirm it’s installed correctly:
/app/solr/bin/solr startand then navigate your browser to http://localhost:8983/solr/. You should the solr admin tool dashboard.
Maria Database
A database is needed for EMERSE. For the purposes of getting started, we’ll use the MariaDB database, since it’s often installable using linux package manages.
sudo dnf install mariadb-serverDatabase servers are often configured to be automatically started up as a "service" when the computer is booted. Different linux systems do this different ways, but the most common, especially for RedHat systems, is systemd. For Fedora, this looks like:
# Enable the service so it starts at boot:
sudo systemctl enable mariadb
# Start it right now:
sudo systemctl start mariadbIf you don’t want it started at boot, don’t "enable" the service. It can be started while "disabled."
To confirm it’s running, run the mariadb command, which attempts to connect to the database:
mariadbYou should either get a command prompt for the database, or a permission error, such as "Access denied for user…" You should not get an error saying it cannot get to the server, or cannot find a file named mysql.sock or a similar name.
Microsoft SQL Server Database
If you are using Microsoft SQL Server as the backend database, we recommend two additional steps to ensure adequate performance.
-
Enable
READ_COMMIT_SNAPSHOTon the database; -
Adding
sendStringParametersAsUnicode=false;on the JDBC connection.
EMERSE Install and Initial Configuration
From here on out, you’ll start installing software developed here at Michigan Medicine. Our software, along with SQL install scripts, and related files are all stored in our private EMERSE project page on GitHub. To access this repository and hence the rest of the installation materials, please contact the EMERSE team and provide us with your GitHub ID.
All installation files are "assets" on release pages of the EMERSE project. Generally, we don’t duplicate all the files needed to install EMERSE on each release, because many files don’t change, and many files that don’t change are extremely large (such as the example index files). For this reason, we only attach the changed files for each release. Thus, if you need a file named, say, emerse.properties you should search from the most recent release to the least recent release for the file with that name, or a very similar name. For instance, if you see emerse.properties on releases 6.1.1, 6.1, and on 6.0, you should use the one from 6.1.1. Similarly, if you are looking for emerse-solr-6.0.jar and you see it on release 6.0 but also see a emerse-solr.jar on release 6.1, you should use the 6.1 version. (We try not to have versions in our file names so that the file name is an exact match across versions.)
| This guide was written when 6.3.0 was the last release, so we’ll tell you to go to a specific release page to get a particular file, but (if at least you are trying to install the latest version) you should always find the latest version of the file by scanning from the most recent release. |
Solr indexes
We provide three indexes with the default distribution. Three of the indexes are populated with sample data to help with testing the initial setup and configuration.
The three indexes are:
-
patient -
patient-slave -
documents
| Do not change the names of these indexes. |
Two of the indexes (patient and patient-slave) store data about the patients (not real patients in the files that we distribute), and are meant to be populated from the PATIENT table within the database. These indexes are required by EMERSE and the overall structure/definition of them should not be changed even for your own localized installation. The patient demographic data stored within them will automatically be replaced from the database tables when EMERSE is running. The two patient indexes are used to rapidly summarize details used for graphing the demographics.
A third index is called documents and holds PubMed abstracts and open access case reports (containing no protected health information) as placeholders for sample documents. For your production system you can optionally rename this to something that is more suitable (you would then have to update the name in the database table called SOLR_INDEX, described in the Data Guide). Additionally, other aspects of the configuration for this document index will have to be changed from the included example to match your local institutional needs (e.g., the metadata types included for each document).
| These three sample indexes can be found on our GitHub page. |
Once you have access to our GitHub repository, navigate to the 6.0 release, and download the following files:
-
pubmed-documents.zip -
pubmed-patient.zip -
pubmed-patient-slave.zip -
solr.xml
Also navigate to the the 6.3.0 release and download the following files:
-
emerse-solr.jar
We’ll create a solr home directory under /app/indexes:
cd /app
mkdir indexes
cd indexes
cp ~/Downloads/solr.xml .
mkdir lib
cp ~/Downloads/emerse-solr.jar lib
unzip ~/Downloads/pubmed-documents.zip
unzip ~/Downloads/pubmed-patient.zip
unzip ~/Downloads/pubmed-patient-slave.zip
Each zip file is a Solr "core" or "index". Solr needs the solr.xml file to exist, but currently contains no settings that we need to specify; all the defaults in Solr are fine. Finally, the lib directory contains our plugin jar to Solr, which is used by the documents index.
|
Once this is done, your directory structure should look like:
/app/documents /app/lib /app/patient /app/patient-slave /app/solr.xml ---
Next, we’ll stop solr, and start it back up, specifying the solr home directory as /app/indexes so it reads these indexes:
/app/solr/bin/solr stop
/app/solr/bin/solr start -s /app/indexesYou should be able to navigate to http://localhost:8983/solr/ again and see three cores in the "Core Selector" dropdown on the left side of the screen. There should be no red banner at the top describing an error.
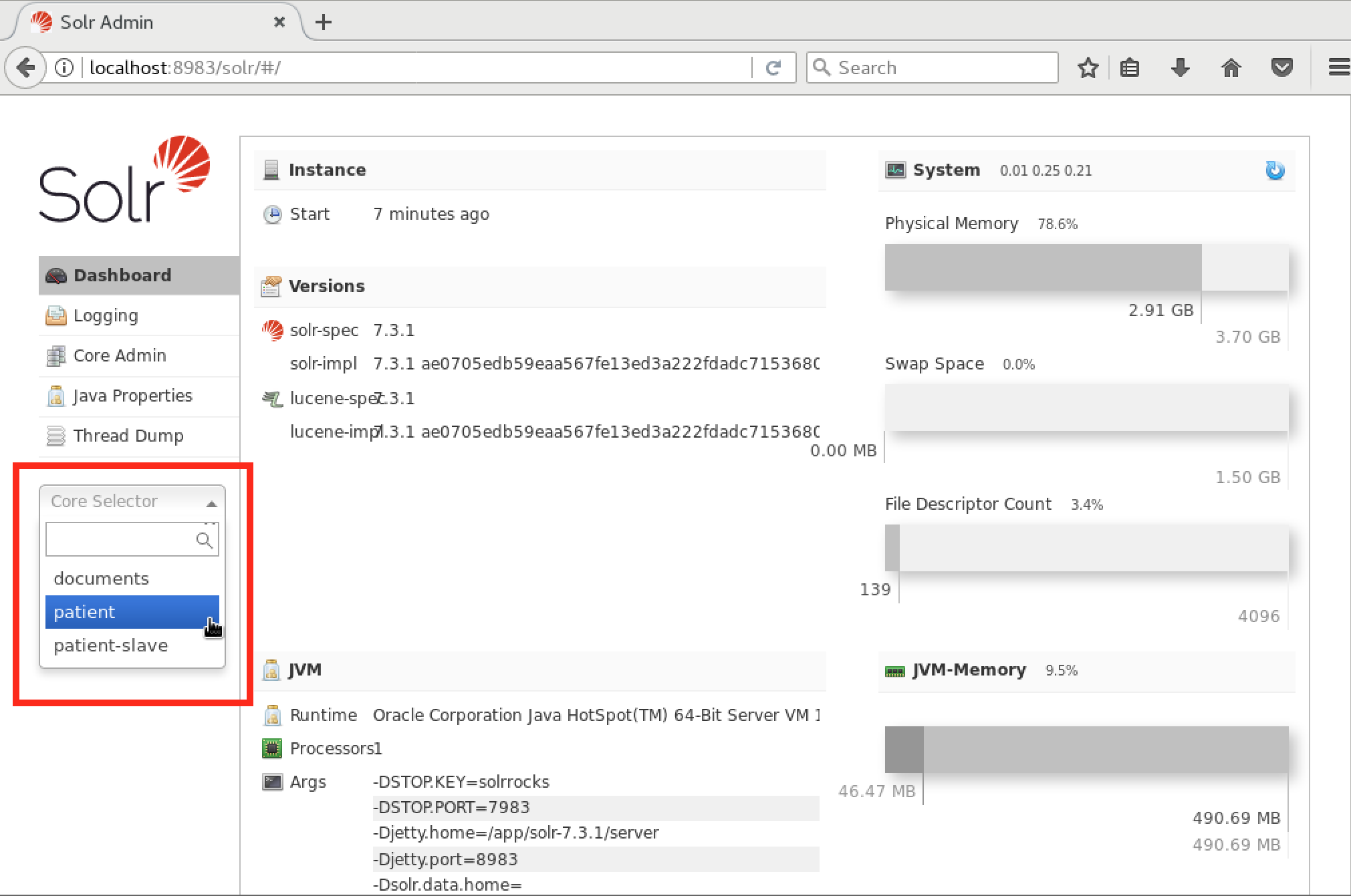
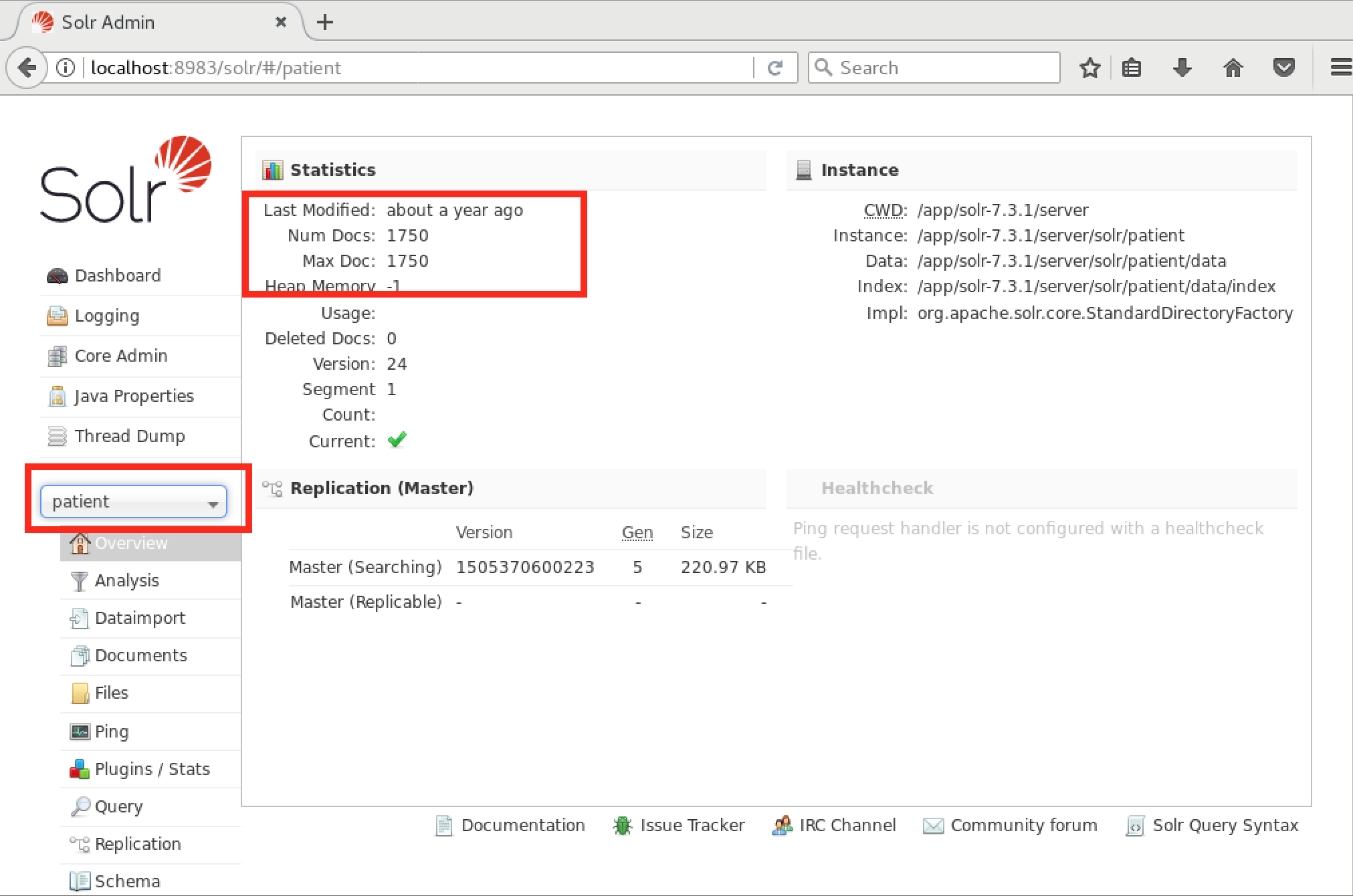
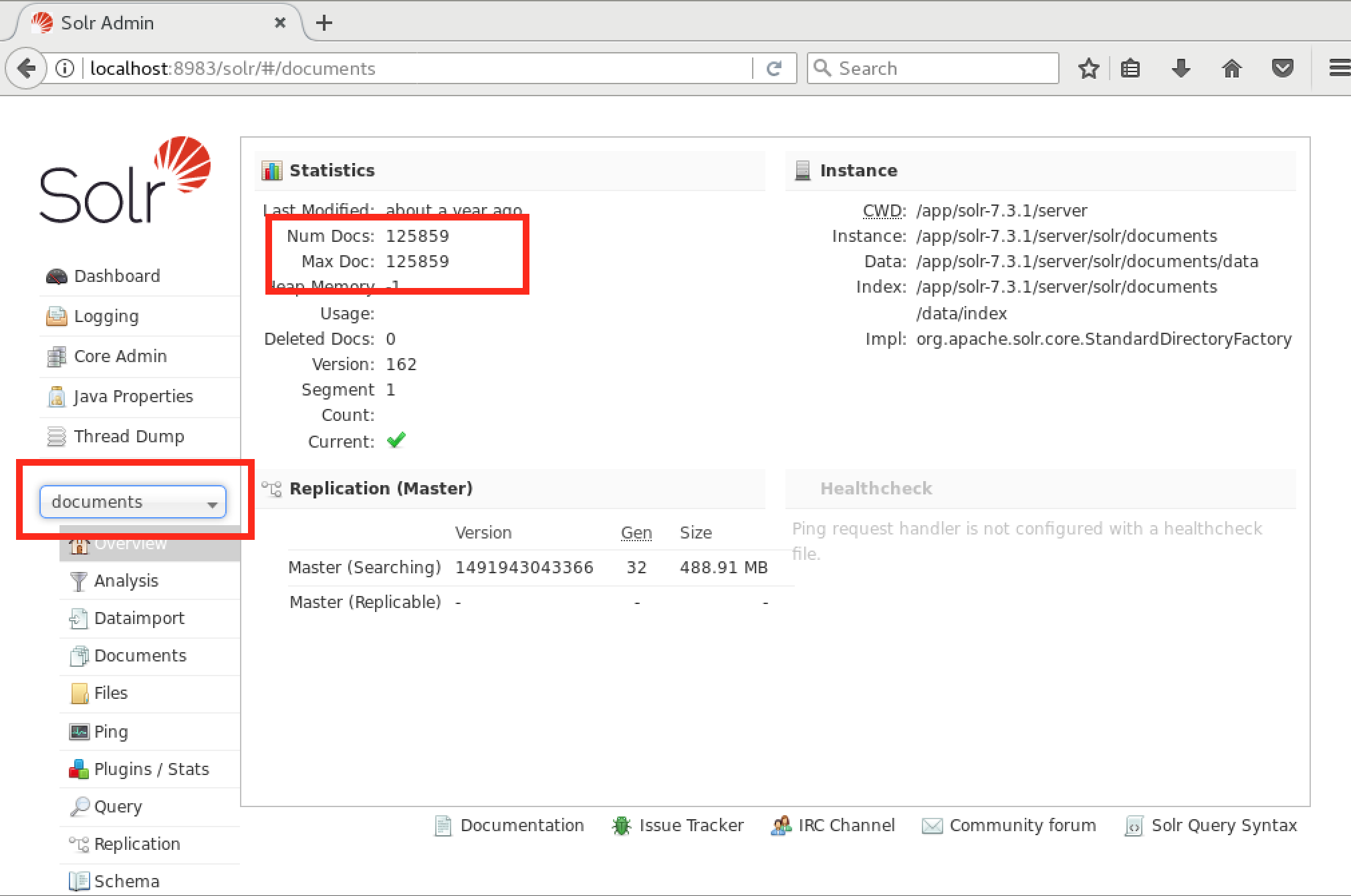
Select each core to verify that the proper counts are there. For the documents core there should be a little over 125,000 documents. For the patient and patient-slave cores, there should be 1750 "documents" (each representing a patient). However, you’ll notice a red error banner for the patient-slave index. To fix this, you’ll have to add the line:
SOLR_OPTS="$SOLR_OPTS -Dsolr.disable.shardsWhitelist=true"to /app/solr/bin/solr.in.sh.
Database initialization
Provided with the EMERSE distribution are a set of files, each containing SQL statements, that create all needed database objects and sample data that will allow the EMERSE application to startup with a default set of database objects, and sample data in the patients, research studies, synonyms and tables. *These scripts should be run as the user and schema setup for the EMERSE application (this will be set by each implementing site) We recommend a schema named emerse. The account doesn’t require a DBA role but needs to be able to create database objects such as tables, indexes, sequences and views.
To run these scripts, we need to create a user and schema for EMERSE. To do that, we need to login to the database as a privileged user. That depends on how the database is set up during installation, which if you installed MariaDB from the Linux distribution package manager, that depends on how they chose to set it up. Thus, you will have to consult the documentation from the Linux distribution on how to login to MariaDB. For Fedora Linux, we merely need to become root user, and issue the mariadb command. Usually either the mariadb or mysql command is used to connect to the database.
sudo su -
mariadbOnce we are connected as a privileged user, we should create the emerse user with password "demouser" and emerse schema (called a "database" in MariaDB parlance) by giving the following commands to the database in the mariadb / mysql commandline:
create user emerse identified by 'demouser';
create database emerse character set = 'utf8';
grant all privileges on emerse.* to emerse;To check that this has been done correctly, login to the bash shell as yourself again (not root), and try:
mariadb emerse -u emerse -pand type the password "demouser". (You may need to use mysql as the command; it’s usage is exactly the same.) This should grant you access to the MariaDB sql commandline. Whenever we need to run sql, you should login to the database using this command, or a similar one.
Go back to the EMERSE GitHub 6.3.0 release page, and download the following files:
-
6.3.0.mariadb.sql
Different database need different sql scripts. Other database should work, but we will need to generate scripts for you. If you are installing on such a database, please email us and we can upload a script for you.
To need to run this file against our emerse database, issue the following command:
mariadb emerse -u emerse -p < ~/Downloads/install_mariadb.sqlYou’ll have to type the password "demouser", and then this command will hang for a minute or so, but should return you back to the prompt without any further text.
To confirm everything was installed correctly, you can log into the database (using mariadb emerse -u emerse -p) and run the SQL:
show tables;And this should list 137 tables.
EMERSE Configuration
EMERSE is configured by primarily one file, emerse.properties. This file tells EMERSE how to connect to Oracle, Solr, and LDAP (if using). It also has additional internal configuration or presentation information such as contact email.
Go back to the GitHub release page for version 6.1 and download the following files:
-
emerse.properties
After downloading, move the properties to /app/etc/.
mkdir /app/etc
mv ~/Downloads/emerse.properties /app/etc/Next, we need to tell Tomcat to tell EMERSE where this file is. We can do that by creating the file /app/tomcat/bin/setenv.sh with the following content:
export CATALINA_OPTS="$CATALINA_OPTS -Demerse.properties.filepath=/app/etc/emerse.properties"This can be done with the following command:
echo 'export CATALINA_OPTS="$CATALINA_OPTS -Demerse.properties.filepath=/app/etc/emerse.properties"' >> /app/tomcat/bin/setenv.shYou will need to make some changes to the emerse.properties file to reflect your installation properties such as the URL of the database. Information on configuring EMERSE application properties is located in the Configuration Guide.
For our installation, we need to replace the following lines in emerse.properties
ds.url=jdbc:oracle:thin:@localhost:1521/orcl
ds.driver=oracle.jdbc.driver.OracleDriver
ds.dialect=org.hibernate.dialect.Oracle12cDialectwith:
ds.url=jdbc:mariadb://localhost:3306/emerse
ds.dialect=org.hibernate.dialect.MariaDB103DialectFor different database, you will need to look up the JDBC url and provide it for the value of ds.url. All databases except Oracle do not need the ds.driver property, so it should be removed. The ds.dialcet is a Hibernate dialect, which should be chosen based on Hibernate’s documentation. Just pick the class name that seems to match your database version most closely.
WAR file installation
The next step in getting EMERSE up and running after initial installation of the application server and configuration of the database with default settings is to deploy the EMERSE WAR file.
Go to the latest EMERSE release page (currently here) and download the emerse.war file.
Install that into tomcat by moving it into the webapps directory:
mv ~/Downloads/emerse.war /app/tomcat/webappsWe also need to download the JDBC database driver. For MariaDB, download the latest stable version here. (For MariaDB, they named the driver "Connector/J".) Their website has a lot of steps; you want to look for the "jar" packaging without sources. The file name should look like mariadb-java-client-VERSION.jar. For instance, a direct like to the most current version at the time of writing is here.
We’ll move the driver into the tomcat lib directory so it’s available to EMERSE:
mv ~/Downloads/mariadb-java-client-*.jar /app/tomcat/lib/Once both emerse.war and the correct database driver are installed into Tomcat, you should be able to restart tomcat and navigate to http://localhost:8080/emerse/ and see the login screen.
/app/tomcat/bin/catalina.sh stop
/app/tomcat/bin/catalina.sh startYou can login as the user emerse with the password demouser. (This account is completely different than the database account, but we use the same username and password so there’s less to remember.)
If the EMERSE application does not come up, check the tomcat logs at: /app/tomcat/logs/catalina.out
Further testing
To test the installation a bit futher, login and try a search:
-
Choose any button or type something in to get past the Attestation page.
-
Enter "chest pain" in the Add Terms Box and press Find Patients.
-
Click on the button Move patients to Temporary Patient List
-
Click the Highlight Documents button
-
Click on cell on the Overview page to see a document with the term "chest pain" highlighted on the following Summaries page.
-
Click on a Summary to open up an actual document with the term "chest pain" highlighted.
At this point, if everything worked, it’s is a very good indication that EMERSE is running well.
Setting startup scripts
While not necessary, it can be helpful to have the system startup every time the server is started or rebooted, rather than entering the startup commands for each component every time. To do this, create a shell script in /app that will contain the commands to launch the two components:
#!/usr/bin/env bash
cd /app
while (( $# ))
do
case $1 in
start)
solr/bin/solr start -s indexes
tomcat/bin/catalina.sh start
;;
stop)
solr/bin/solr stop
tomcat/bin/catalina.sh stop
;;
esac
shift
doneMake the script executable:
chmod +x emerseThis script assumes the database starts up on reboot already. If you chose not to do that when you install the database and what to do that now, it should be a command similar to
sudo systemctl enable mariadbbut it depends on your linux distribution, or how you installed your database. Alternately, you can add the database start and stop commands to this script.
Now add that startup script to a crontab. To create the file, type:
crontab -eIf you have followed the directions outlined in this document and installed Redhat Linux, it may open up the file using the vi editor. If so, type i for insert, then type one line as follows:
@reboot /app/emerse startThen, to save the file, type esc [escape] and then :wq and enter to close and save the file. To verify that the crontab is there, type
crontab -lIt should show the line above (beginning with @reboot). At this point, restarting the server should allow all of the required components to startup automatically.
Customizing EMERSE
Once an initial implementation is complete, local customization work will need to be done including identifying document sources, proper indexing with metadata in Solr, and other configurations related to document display in EMERSE.
At a high level, you’ll have to:
-
Gain access to patient demographic data such as name, date of birth, sex, race, etc. We’ll use these data to fill the PATIENT database table.
-
Build a process to pull in patient data into EMERSE’s PATIENT table as patient data is added or changed.
-
Gain access to the free text patient notes. There may be multiple systems storing patient notes. EMERSE can be loaded with all of them.
-
Decide on the schema of Solr documents used to store patient notes. This means what field names are you going to use, and are these fields going to store dates, text, or some other metadata (such as note type, clinical department, etc).
-
Update the schema in your Solr index to reflect your decision.
-
Update the DOCUMENT_FIELDS table and related tables to reflect your Solr schema, and decide what fields are visible on what screens in EMERSE.
-
Build a process to push (or pull) patient notes into Solr, as new notes are created, and old notes are amended or corrected.
You’ll probably have your patient demographic data and patient notes in a database, but you could also have a "feed" of notes or other events, such as HL7 messages, sent to you over a message queue or pubsub system. If your best access is the feed, we recommend you store the messages into a database for EMERSE, since EMERSE will require you to re-index all documents on certain major upgrades. In those cases, pulling from a database is often easier or faster than getting the HL7 feed to be replayed, or extracting the stored documents out of the old instance of Solr to be indexed into the new instance.
EMERSE has a concept of a source. A source isn’t defined by where documents come from, per se, though often it has some connection to that. Instead, each source defines the set of fields for its documents, so if you have two documents with different sets of fields, they should be labeled with different sources. Of course, it is also possible for some documents labeled with one source to not use certain fields, or use certain fields differently, however sources are meant to mitigate this usage, since it can be misleading, or lead to very generic labels for fields which may be unhelpful. It’s up to you to decide how to organize documents into EMERSE’s sources.
For the purpose of this guide, let’s suppose we have our documents and patients stored in a database, and there are three sources of documents:
-
Encounter Notes
-
Radiology Reports
-
Pathology Reports
And suppose we have this hypothetical warehouse in which these documents are stored:
create table PROVIDER (
ID bigint primary key,
NAME varchar(128)
);
create table PROCEDURE (
ID bigint primary key,
NAME varchar(128),
CATEGORY bigint,
);
create table ORDERED_PROCEDURE (
ID bigint primary key,
PROC_ID bigint foreign key PROCEDURE (ID),
PAT_MRN_ID varchar(20),
AUTHORIZING_PROV_ID bigint foreign key PROVIDER (ID),
CSN bigint,
RESULT_STATUS varchar(24),
RESULT_DATE datetime,
REPORT_DATE datetime,
UPDATE_DATE datetime
);
create table IMPRESSION (
ORDERED_PROC_ID bigint not null foreign key ORDERED_PROCEDURE (ID),
LINE_NUM smallint not null,
LINE varchar(1024),
primary key (ORDERED_PROC_ID, LINE_NUM)
);
create table NARRATIVE (
ORDERED_PROC_ID bigint not null foreign key ORDERED_PROCEDURE (ID),
LINE_NUM smallint not null,
LINE varchar(1024),
primary key (ORDERED_PROC_ID, LINE_NUM)
);
create table ENCOUNTER (
ID bigint primary key,
PAT_MRN_ID varchar(20),
AUTHORIZING_PROV_ID bigint foreign key PROVIDER (ID),
CSN bigint,
ENCOUNTER_DATE datetime,
UPDATE_DATE datetime,
ENCOUNTER_TYPE varchar(128),
TEXT mediumtext
);Encounters are stored entirely in the ENCOUNTER table, containing a clob of the entire report. Both ordered procedures and encounters reference providers by a foreign key. We have a set of procedures grouped into categories, which is how we’ll distinguish between radiology and pathology reports. If a procedure is ordered, it can have an impression or narrative or both. Those tables split the text for a single ordered procedure across many rows, ordered by the LINE_NUM column.
Obviously, real systems would have more rational organization of data.
Declaring Solr Fields to EMERSE
EMERSE has three tables describing Solr fields and field values:
-
DOC_FIELD_EMR_INTENTdefines what fields are used for very general purposes, such as text search and date range filtering, and unique identification. -
DOCUMENT_SOURCEdefines what values may appear in theSOURCEfield; these are the sources. -
DOCUMENT_FIELDSdefines what fields are used for what sources, how they should be labeled for those sources, and the type of data stored in them.
Solr’s schema design and these tables are independent in the sense that changing one doesn’t affect the other, but they need to be consistent in order for EMERSE to work correctly. Despite EMERSE having the concept of multiple sources, all documents go into the same index in Solr, and so there is only one set of fields available to all documents, but not all documents need to use them, though they have to use fields consistently at a basic type level. For instance, a field PROVIDER can’t store text for one source and then a number for another source. (Of course, it could store the number as text, but that precludes range queries, for instance.)
DOC_FIELD_EMR_INTENT
EMERSE needs certain data stored in the same field for all sources because it does certain operations across all sources, or wants to do certain operations in a source-independent way. These fields are listed in DOC_FIELD_EMR_INTENT table. You should not add or remove rows from this table, but only change the SOLR_FIELD_NAME column. For our example, let’s decide on the following fields in Solr for the given EMR intent rows:
| Solr Field | Purpose | DOC_FIELD_EMR_INTENT name |
|---|---|---|
|
Case-sensitive text |
|
|
Case-insensitive text |
|
|
Medical record number |
|
|
Cross-source unique document identifier |
|
|
Date document was updated |
|
|
Date used for date-filtering in EMERSE |
|
These decision directly lead to the following SQL:
update DOC_FIELD_EMR_INTENT
set SOLR_FIELD_NAME = 'TEXT_CS'
where NAME = 'RPT_TEXT_NOIC';
update DOC_FIELD_EMR_INTENT
set SOLR_FIELD_NAME = 'TEXT'
where NAME = 'RPT_TEXT';
update DOC_FIELD_EMR_INTENT
set SOLR_FIELD_NAME = 'MRN'
where NAME = 'MRN';
update DOC_FIELD_EMR_INTENT
set SOLR_FIELD_NAME = 'ID'
where NAME = 'RPT_ID';
update DOC_FIELD_EMR_INTENT
set SOLR_FIELD_NAME = 'UPDATED'
where NAME = 'LAST_UPDATED';
update DOC_FIELD_EMR_INTENT
set SOLR_FIELD_NAME = 'DATE'
where NAME = 'CLINICAL_DATE';Cleaning up old Sources and Fields:
We modified the DOC_FIELD_EMR_INTENTE table, but the other two should be cleared out, and we’ll insert new rows for the fields as we decided on what we’ll store. We’ll go source by source.
delete from DOCUMENT_FIELDS;
delete from DOCUMENT_SOURCE;The encounter Source
Let’s start with the encounter source. We need to decide
-
what from the data warehouse we will store in Solr, and
-
where we will show that data in EMERSE.
Not all data needs to be visible in EMERSE; with advanced search, it is possible to have data in Solr that can be used in search, but never shown to the user.
There are two places we can show a field:
-
when viewing the whole document, or
-
when viewing a list of documents for a specific source and patient
If the field is visible, we can also give it a label, which will appear as the column header if its shown in the list of documents, or a row header if shown in the whole-document view.
| Solr Field | Purpose | Visible in Views | Label |
|---|---|---|---|
|
Cross-source unique id |
nowhere |
|
|
MRN |
whole |
MRN |
|
Encounter date |
list, whole |
Encounter Date |
|
Date document updated |
whole |
Updated Date |
|
Source-specific id |
whole |
Encounter ID |
|
Name of the clinician |
list, whole |
Provider |
|
ID of the clinician |
nowhere |
|
|
CSN |
whole |
CSN |
|
Type of encounter |
list, whole |
Encounter Type |
This directly translates to some SQL:
insert
into DOCUMENT_SOURCE
( SOURCE_KEY, USER_DESCRIPTION
, HTML_FLAG, PRELIMINARY_DOC_FLAG
, DISPLAY_NAME, CSS_DISPLAY_PREFIX
, DISPLAY_ORDER, EXTERNAL_SOURCE )
values
( 'encounter', 'Encounters'
, 1, 0,
, 'Encounters', null,
, 1, 0 );
insert
into DOCUMENT_FIELDS
( DOCUMENT_SOURCE_KEY, DISPLAY_ORDER
, TYPE
, SOLR_FIELD_NAME, DATATYPE
, EMR_INTENT
, DISPLAY_NAME, SUMMARY_DISPLAY_FLAG, DISPLAY_FLAG
)
values
( 'encounter', 1
, 'STANDARD'
, null, null
, 'RPT_ID'
, null, 0, 0
),
( 'encounter', 2
, 'STANDARD'
, null, null
, 'MRN'
, 'MRN', 0, 1
),
( 'encounter', 3
, 'STANDARD'
, null, null
, 'CLINICAL_DATE'
, 'Encounter Date', 1, 1
),
( 'encounter', 4
, 'STANDARD'
, null, null
, 'LAST_UPDATED'
, 'Last Updated', 0, 1
),
( 'encounter', 5
, 'CUSTOM'
, 'SSID', 'TEXT'
, null
, 'ID', 0, 1
),
( 'encounter', 6
, 'CUSTOM'
, 'PROVIDER', 'TEXT'
, null
, 'Provider', 0, 1
),
( 'encounter', 7
, 'CUSTOM'
, 'CSN', 'TEXT'
, null
, 'CSN', 0, 1
),
( 'encounter', 8
, 'CUSTOM'
, 'TYPE', 'TEXT'
, null
, 'Note Type', 1, 1
)
;The columns CSS_DISPLAY_PREFIX, EXTERNAL_SOURCE, PRELIMINARY_DOC_FLAG, and DESCRIPTION are all unused, so their values does matter.
Notice that we had to define the columns for the EMR intentions, but didn’t have to make them visible. This makes sense for some columns, such as the RPT_ID intent, since it is a unique identifier, and we have an SSID. Notice that we didn’t declare the field PROVIDE_ID to EMERSE, since we don’t want it visible anywhere; we will just use it in advanced search. We could declare it to EMERSE, but if it isn’t visible anywhere, it serves no purpose.
| See the configuration guide for more detail on these columns. |
The reports Source
We’ll put both radiology and pathology reports in the same source since they have some different fields than encounters, but similar fields to each other; after all, they are described using the same tables in the warehouse, the only difference is the procedure category.
| Solr Field | Purpose | Visible in Views | Label |
|---|---|---|---|
|
Cross-source unique id |
nowhere |
|
|
MRN |
whole |
MRN |
|
Result date |
list, whole |
Result Date |
|
Date document updated |
whole |
Updated Date |
|
Source-specific id |
whole |
Encounter ID |
|
Name of the clinician who authorized the procedure |
list, whole |
Provider |
|
CSN |
whole |
CSN |
|
Status of the result |
list, whole |
Encounter Type |
|
Date the report was made |
whole |
Report Date |
This directly translates to some SQL:
insert
into DOCUMENT_SOURCE
( SOURCE_KEY, USER_DESCRIPTION
, HTML_FLAG, PRELIMINARY_DOC_FLAG
, DISPLAY_NAME, CSS_DISPLAY_PREFIX
, DISPLAY_ORDER, EXTERNAL_SOURCE )
values
( 'reports', 'Reports'
, 1, 0,
, 'Reports', null,
, 2, 0 );
insert
into DOCUMENT_FIELDS
( DOCUMENT_SOURCE_KEY, DISPLAY_ORDER
, TYPE
, SOLR_FIELD_NAME, DATATYPE
, EMR_INTENT
, DISPLAY_NAME, SUMMARY_DISPLAY_FLAG, DISPLAY_FLAG
)
values
( 'reports', 1
, 'STANDARD'
, null, null
, 'SSID'
, null, 0, 0
),
( 'reports', 2
, 'STANDARD'
, null, null
, 'MRN'
, 'MRN', 0, 1
),
( 'reports', 3
, 'STANDARD'
, null, null
, 'CLINICAL_DATE'
, 'Report Date', 1, 1
),
( 'reports', 4
, 'STANDARD'
, null, null
, 'LAST_UPDATED'
, 'Last Updated', 0, 1
),
( 'reports', 5
, 'CUSTOM'
, 'SSID', 'TEXT'
, null
, 'ID', 0, 1
),
( 'reports', 6
, 'CUSTOM'
, 'PROVIDER', 'TEXT'
, null
, 'Authorizing Provider', 0, 1
),
( 'reports', 7
, 'CUSTOM'
, 'CSN', 'TEXT'
, null
, 'CSN', 0, 1
),
( 'reports', 9
, 'CUSTOM'
, 'STATUS', 'TEXT',
, null
, 'Result Status', 0, 1
),
( 'reports', 10
, 'CUSTOM'
, 'REPORT_DATE', 'DATE'
, null
, 'Report Date', 1, 1
);Configuring Solr
Once we have declared the fields we will use in Solr to EMERSE, we should setup Solr to actually use those fields. You can delete the data directories inside each core:
/app/solr/bin/solr stop # don't run solr while reconfiguring it
rm -Rf /app/indexes/*/dataThen edit the /app/indexes/documents/conf/managed-schema to remove all fields, but keep all the data types, then add our fields:
<?xml version="1.0" encoding="UTF-8"?>
<schema name="example" version="1.5">
<!-- must name the field that stores the unique key of the document across all sources -->
<uniqueKey>ID</uniqueKey>
<!-- required for internal Solr reasons -->
<field name="_version_" type="long" docValues="true"/>
<!-- fields for DOC_FIELD_EMR_INTENT table -->
<field name="ID" type="string" required="true"/>
<field name="SOURCE" type="string" docValues="true"/>
<field name="MRN" type="string" docValues="true"/>
<field name="DATE" type="date" docValues="true"/>
<field name="UPDATED" type="date" docValues="true"/>
<field name="TEXT" type="text_general_htmlstrip" termPositions="true" termVectors="true" termOffsets="true"/>
<field name="TEXT_CS" type="text_general_htmlstrip_nolowercase" termPositions="true" termVectors="true" termOffsets="true" stored="false"/>
<!-- Tell Solr to use the value of the TEXT field as the value for the TEXT_CS field -->
<copyField source="TEXT" dest="TEXT_CS"/>
<!-- shared fields -->
<field name="SSID" type="string" docValues="true"/>
<field name="PROVIDER" type="string" docValues="true"/>
<field name="PROVIDER_ID" type="numeric" docValues="true"/>
<field name="CSN" type="string" docValues="true"/>
<!-- encounter specific fields -->
<field name="TYPE" type="string" docValues="true"/>
<!-- reports specific fields -->
<field name="STATUS" type="string" docValues="true"/>
<field name="REPORT_DATE" type="date" docValues="true"/>
<!-- the field types should be here -->
</schema>Generally, all fields should have docValues="true" unless it is one of the text fields. Fields are stored and indexed by default, but the field mapped to by the RPT_TEXT_NOIC emr intent (TEXT_CS in our case) should not be stored since its value should be a copy of the field mapped to by the RPT_TEXT emr intent (TEXT in our case) so we already have it stored, and don’t need a second copy of it. The two text fields also need additional attributes set as shown for EMERSE to be able to highlight and search.
Once we have rewritten our index schema, we can start solr again and start indexing.
Indexing into Solr
You will need to develop an ETL process to load documents into EMERSE from your document sources. The EMERSE team has an application called "EMERSE Indexing" that indexes documents formed from queries to databases into Solr which we will use to show how this could be done. You can contact the EMERSE team to get the application. Looking at the code should give you an example of how you can do this yourself, or if your data source are all in databases, you may be able to use the application yourself.
EMERSE Indexing requires three things:
-
Apache Tomcat,
-
Apache ActiveMQ, and
-
a database.
At UM, we use a instance Tomcat just for indexing, but for this guide, we’ll use the same one as EMERSE. Put the indexing.war in /app/tomcat/webapps/indexing.war and adjust add some lines to /app/tomcat/bin/setenv.sh to tell it where its configuration files are:
export CATALINA_OPTS="$CATALINA_OPTS -Demerse-indexing.properties.filepath=/app/etc/emerse-indexing.properties"
export CATALINA_OPTS="$CATALINA_OPTS -Ddocuent-sources.xbl.filepath=/app/etc/document-sources.xml"Now let’s define the properties:
broker.url=tcp://localhost:61616
solr.url=http://localhost:8983/solr/documents
solr.fields=ID,SOURCE,MRN,DATE,UPDATED,TEXT,SSID,PROVIDER,PROVIDER_ID,CSN,TYPE,STATUS,REPORT_DATE
ds.dw.url=jdbc:...
ds.dw.username=...
ds.dw.password=...
ds.dw.driver=...
ds.emerse-indexing.url=jdbc:mariadb:localhost:3306/indexing
ds.emerse-indexing.username=emerse
ds.emerse-indexing.password=demouserThe field solr.fields should list out all our solr fields. The properties starting like ds.<name> give connection details for a database called <name>. We’ll use two database, one called "dw" which would be your data warehouse, and "emerse-indexing" which is a required database that stores the tables EMERSE Indexing itself uses. We’ll create a database in MariaDB for this.
Create a database and run the install sql script for the indexing project, much like for EMERSE:
create database indexing character set = 'utf8';
grant all privileges on indexing.* to emerse;mariadb indexing -u emerse -p < indexing.mariadb.sqlFinally, the indexing application requires a durable message broker called ActiveMQ "classic" edition. We can download and install it much like tomcat, from apache’s website. Expand the zip in /app/, renaming it to activemq, then starting it:
cd /app
unzip ~/Downloads/apache-activemq-*.zip
mv apache-activemq* activemq
# and start it
activemq/bin/activemq startWe can use the default configuration for activemq. You should see the admin interface at http://localhost:8161/admin/. The username and password are both admin.
Next, we will write the document-sources.xml. A quick overview of the project is needed, but I won’t cover everything here. You can see the documentation for the project on GitHub for more details.
The indexing application has a notion of a "source", and is defined by a <source> element in the XML. It has a name attribute, used within the application to load documents from the source, plus a source attribute which is assigned to the SOURCE field of the documents produced from it. (That is, it’s the EMERSE source.) Thus, multiple indexing sources can go into the same source bucket in EMERSE.
There are two kinds of queries in the indexing application. A document metadata query, which produces the metadata for documents, one document per row produced by the query, and a text query, which produces the text of the document. The text query is run once for each document, and the first column of all rows of produced by the query are appended together to produce the text of the document.
There are three variations on the metadata query, which differ only which documents they pick out, but always return the same set of columns. They are:
-
<range>query, returning documents in a date range, -
<incremental>query, returning documents modified since the last run of the incremental query, -
<by-keys>query which return documents enumerated by unique keys identifying the documents stored in a table.
Each of these queries are defined under a common element <documentQueries> under the <source>. However, since the queries return the same data, but only for different subsets of all documents, they differ only slightly in the where clause. For that reason, instead of writing out the whole query under each element, they are defined as a substitution of "fragment references" on a single <baseDocumentQuery> (under the <source> element). The fragment references are written like ##fragment-name##. The replacement for the fragment references are defined by a like-named element under the variation’s element under <documentQueries>. Some example XML is helpful here:
<source name="pathology" source="reports">
<documentBaseQuery>
select a.columnA as SOLR_FIELD_A
, b.columnB as NON_SOLR_COLUMN
from tableA a
join tableB b on a.ID = b.A_ID
where ##selection-criteria##
</documentBaseQuery>
<documentQueries>
<range>
<selection-criteria>a.DATE between :from and :to</selection-criteria>
</range>
<incremental>
<selection-criteria>a.UPDATE_DATE > :lastUpdated</selection-criteria>
</incremental>
<by-keys>
<selection-criteria>a.ID = :key1</selection-criteria>
</by-keys>
</documentQueries>
<textQuery>
select line
from table
where abc = :SOLR_FIELD_A
and def = :NON_SOLR_COLUMN
</source>Note that if multiple fragment references are present in the base query, then you’d define each as additional elements under the variation’s element (as a sibling to <selection-criteria> in the example above). Also note that the different variations have different query parameters, written in the form of :parameterName. These are fixed for each of the variations, and are as shown in the example.
Finally, in the text query, you reference the column aliases of the metadata query as query parameters. Thus, you can return some columns only needed in the text query (to make it run faster by doing fewer joins). The column aliases of the metadata query do double-duty by naming the field that column should be placed in. If the column alias isn’t in the solr.fields property in emerse-indexing.properties it won’t be added to the solr document.
We will define two indexing sources, matching our EMERSE sources. We will only work with the range metadata query, since it’s the most straightforward.
<sources>
<source name="reports" source="reports">
<baseDocumentQuery>
select proc.ID as PROC_ID
, 'r' || oproc.ID as ID
, oproc.ID as SSID
, oproc.PAT_MRN_ID as MRN
, oproc.RESULT_DATE as DATE
, oproc.UPDATE_DATE as UPDATED
, oproc.AUTHORIZING_PROV_ID as PROVIDER_ID
, prov.NAME as PROVIDER
, oproc.CSN as CSN
, oproc.REPORT_DATE as REPORT_DATE
, oproc.RESULT_STATUS as STATUS
from ORDERED_PROCEDURE oproc
join PROVIDER prov
on prov.ID = oproc.AUTHORIZING_PROV_ID
join PROCEDURE proc
on proc.ID = oproc.PROC_ID
where proc.CATEGORY in (1, 2)
and ##condition##
</baseDocumentQuery>
<documentQueries>
<by-keys/>
<incremental/>
<range>
<condition>oproc.RESULT_DATE between :from and :to</condition>
</range>
</documentQueries>
<textQuery>
select *
from (
select NAME, 1 as section, 0 as line
from PROCEDURE
where ID = :PROC_ID
union all
select 'IMPRESSION\n\n', 2 as section, 0 as line
union all
select LINE, 3 as section, LINE_NUM as line
from IMPRESSION
where ORDERED_PROC_ID = :SSID
union all
select '\n\nNARRATIVE\n\n', 4 as section, 0 as line
union all
select LINE, 5 as section, LINE_NUM as line
from NARRATIVE
where ORDERED_PROC_ID = :SSID
) t
order by t.section, t.line
</textQuery>
</source>
<source name="encounters" source="encounters">
<baseDocumentQuery>
select 'e' || ID as ID
, e.ID as SSID
, e.PAT_MRN_ID as MRN
, e.ENCOUNTERDATE as DATE
, e.UPDATE_DATE as UPDATED
, e.AUTHORIZING_PROV_ID as PROVIDER_ID
, prov.NAME as PROVIDER
, e.CSN as CSN
, e.ENCOUNTER_TYPE as TYPE
from ENCOUNTER e
join PROVIDER prov
on prov.ID = e.AUTHORIZING_PROV_ID
where ##condition##
</baseDocumentQuery>
<documentQueries>
<by-keys/>
<incremental/>
<range>
<condition>e.ENCOUNTER_DATE between :from and :to</condition>
</range>
</documentQueries>
<textQuery>
select e.TEXT
from ENCOUNTER e
where e.ID = :SSID
</textQuery>
</source>
</sources>Notice in particular, that in the reports source, we produced the PROC_ID column in the metadata query, but it isn’t listed in the solr.fields property. We did this so we can use it in the text query, where we include the name of the procedure at the top of the document’s text, without having to do any joins to find it. Also notice that we construct the text of the document as a series of unions of queries, part of them are fixed text that can be used as section titles. The first column of the rows are joined together to make the text. Other columns are ignored, and only used to order the rows correctly.
Now you should be able to start tomcat and navigate to http://localhost:8080/indexing/. There you will see a very simple interface, where you can tell it to do one of the three variations on the metadata query. Run the range query for a date range that makes sense, and the application should index into Solr.
Useful Post-Implementation Details
-
The
solrconfig.xmlfile should be located on the server. It is located inside/app/indexes/documents/conf/(where "documents" is the name of the Solr core/collection). -
For changes made to the Solr
schema.xmlyou will need to make corresponding changes in the EMERSE database, described in the Data Guide. -
When interacting with the Solr API you may need to use a URL that points to the specific index/collection, such as https://localhost:8983/solr/documents/. However, to get anything back you will need to specify an action such as
https://localhost:8983/solr/documents/select?q=RPT_TEXT:asthma
-
As you are updating the underlying data, note that the patient counts shown in the user interface do not come from the patient database table, but rather is derived from a unique count of the medical record numbers (MRNs) in the indexed documents. This was intentional because it might be the case that a patient in the database has no documents, and thus would return no results within EMERSE. The actual source of the patient count that the GUI uses is in the
SOLR_INDEXdatabase table (thepatient_countcolumn). This column is updated by the app in the background using an async batch process that runs occasionally to update the patient count by retrieving unique MRN’s from the Solr index calleddocuments. An update of the counts for the UI can be forced by the "System Synchronization" feature found within the EMERSE admin application (http://localhost:8080/emerse/admin2/).