
Overview
This guide is meant to provide additional information about troubleshooting various problems that an admin/developer may run into. Additionally it provides guidance on other issues that may be helpful when operating the system if certain problems arise.
If you do run into problems and need our assistance, please be prepared to provide screen shots of the error messages as well as log files.
We recommend that issues get posted to our Discourse Message Forum so that they can be available to all of our developers as well as the larger EMERSE community. The forum is also a good place to search for issues that may have already been addressed.
Log Files
The log files may be very helpful in tracking down problems with EMERSE, and will likely be needed if you need to contact the EMERSE development team for technical support. To help with troubleshooting we have built a basic Log Viewer into EMERSE. This can be found on the Log tab of the Admin application.
Diagnostic Checklist
EMERSE provides a high level 'diagnostic page' (diagnostics.html) that checks to make sure various components of EMERSE are available and responsive, including the database, ActiVQ, and Solr. This may be most helpful when working on an installation of EMERSE. Details about how to access this page can be found in the Installation Guide. Checking the diagnostics on this page is probably one of the best things to first do when looking into problems.
The Log Viewer is available in both the EMERSE Admin Application (see: Administrator Guide) and on the diagnostic checklist page (see: Installation Guide). Note that on the diagnostic checklist page, the log files are only accessible if a hardened profile has not yet been activated. Otherwise it will be necessary to login to the Admin page to view the log data.
The viewer shows recent content from the EMERSE application log. The log may show details of a configuration problem, or other unforeseen errors while EMERSE is running. This log does not show errors from Tomcat itself. The default configuration will only show errors, but it can be optionally configured to show debug and tracing output.
The log feature is only available if the log4j2.xml file, inside the deployed WAR file (WEB-INF/classes/log4j2.xml), has an included appender for EMERSE. The default EMERSE distribution already has this enabled, but if you wish to confirm or have more manual control over the log4j configuration, the relevant portion of configuration is shown below.
<Configuration status="warn"><!-- set status="debug" for lots of info from log4j iteself -->
<Appenders>
<Console name="STDOUT" >
<PatternLayout>
<pattern>%p: [%d{ISO8601}] %c.%M()%L %m%n</pattern>
</PatternLayout>
</Console>
<EmerseApplication name="EMERSE" numBuffers="10" bufferSize="10000">
<ThresholdFilter level="ERROR"/>
<PatternLayout>
<pattern>%p: [%d{ISO8601}] %c.%M()%L %m%n</pattern>
</PatternLayout>
</EmerseApplication>
</Appenders>To show additional, non-error messages in the EMERSE application log, the level setting above can be modified to a different value. Valid values are: TRACE, DEBUG, INFO, WARN, and ERROR.
For example:
<ThresholdFilter level="DEBUG"/>Problems during setup
Some issues may occur during the initial setup of the system because changes made to the database or Solr indexes might now show up in the UI immediately. For example, new patients are loaded into the Patient database table, and then these patients are not visible in the EMERSE UI. This is because EMERSE invokes some data synchronization and update events once per day (overnight, by default). To see these changes immediately it will be necessary to invoke a data synchronization process. This can be done via the System Synchronization feature available through the admin app.
Documents Not Showing Up in EMERSE
If documents added to the index are not showing up in EMERSE, it may be because the Solr index needs to be refreshed, or EMERSE needs to be made aware of the changes. This behavior might occur especially during initial setup and testing where a document is added to the index but then is not visible within EMERSE. Sometimes this behavior might be manifested in a case where a document can be identified during an All Patient search, but then isn’t visible when using a Patient List or within the Overview section of the EMERSE user interface. To force EMERSE to see the document index changes immediately:
-
Login to the EMERSE application under the admin role, and complete the Attestation page.
http://emersehost:port/emerse/login.html
-
Visit the following URL and press
return:http://emersehost:port/emerse/springmvc/admin/refresh/indexes
This should allow the EMERE application to see changes in the Solr index files, once the indexing is complete.
Patient Indexes
Rebuilding Patient Indexes
There may be times when the need arises to rebuild the Solr patient index. For example, if you are working on setting up the system and have just added patients to the database table, that change won’t be reflected within EMERSE immediately since typically the patient data are copied from the Patient database table to the Solr patient index only once per day through a scheduled job (see: Configuration Guide).
To force the copying/indexing to happen on demand, the following directions describe how this can be done, as described in the Administrator Guide.
-
First, login to EMERSE and access the Admin application, which can be found in the pull down menu in the upper right of the browser window.
-
Second, Go to the "System" tab and press the Synchronize button.
This should invoke a process that copies the Patient table from the database over to the Solr patient index. This page will not provide feedback about when it is complete, so then visit this URL to see when it is done:
http://emersehost:port/solr/#/patient
This URL shows the status of the patient index. You can find it by looking for the Last Modified time under Statistics. It won’t say 'complete', but it should report a very recent time frame, such as within the last few minutes. If not, wait until it is complete. Refresh the page from time to time to see if the Last Modified status has changed.
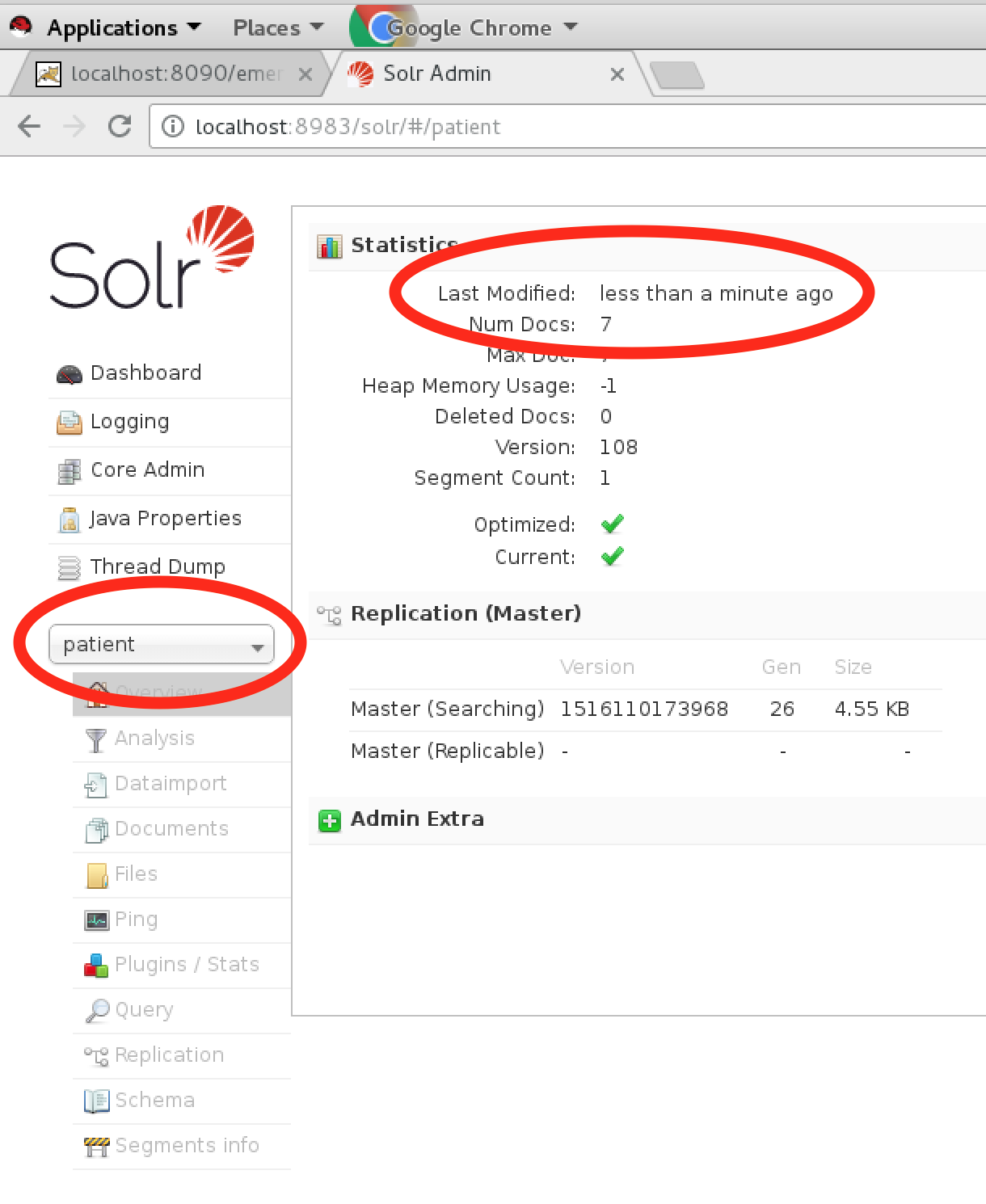
Also note that during an initial setup, it would be expected that the number of patients in the index (defined as "Num Docs" in the Solr admin UI; see screen shot above) should match the number of patients in the Patient database table. This is a good way to check to make sure that the data are syncing correctly. However, over time these numbers may diverge, with the number of patients in the Solr index smaller than the number of patients in the database table. This would occur as patients are logically deleted from the Patient database table, by marking them with deleted_flag=1. Deleted patients are not copied from the database Patient table to the Solr patient index.
Demographic Charts not Loading
If the charts for demographics do not display, or display incorrectly, after running a search across All Patients, there may be a problem with the mapping of the demographics. EMERSE requires demographics to be coded and they should match the contents of the look-up tables within the relational database. If they don’t match, an error will occur and the charts may not get displayed properly.
Another reason they might not load is if the patients in the relational database do not match the patients in the Solr patient index, so this is also worth checking into.
Updates to the Project.Properties File
The project.properties file is where the majority of configuration options are available for EMERSE. As the software gets updated the properties in this file are likely to change over time, especially as new properties are added. This file is another good place to check for discrepancies if there are errors running EMERSE.
User Reports Some Buttons Grayed Out/Not Accessible
If a user reports that some buttons are grayed out or not accessible, it may be because their roles/privileges were set incorrectly. This can be checked and modified from within the EMERSE Admin app (see: Administrator Guide). Additional details about roles and privileges can be also found in the Administrator Guide.
EMERSE not starting up as expected
We have found that EMERSE has a dependency such that the database must be running when EMERSE is started up through Tomcat. If the database is not running, EMERSE will fail to launch and the application will not be available. Make sure that when the various components are started that the database is started first and enough time is given to allow it to be running and responsive before Tomcat is started.
Difficulty uploading a Synonyms file
Synonyms files are simple text-bases TSV files, and they can be uploaded via the administrator interface. There have been occasions in which this file could not be uploaded. We have so far found two possible causes for this:
-
If you see the error:
Uncaught error in application: Syntax Error: JSON.parse: unexpected character at line 1 column 1 of the JSON datathis might be caused by a proxy web server that caps the size of uploaded files. Removing this limit, or allowing the files to go directly to the underlying Tomcat webserver should be able to solve this problem. -
Other errors might still be due to the server’s limit on the size of files that can be uplaoded, since some synonyms files can be large (e.g., greater than 50 MB). In such cases it will be important to make sure that this file size limit is not the issue. This has to be configured on the server side; it is not an EMERSE-specific configuration issue.
-
If you see an error similar to:
unable to extend index EMERSE.SYNONYMS_LCASE by 128 in tablespace SYSTEMit might mean that your database has not been allocated enough space. To increase the space, contact your DBA.
Slow counts for Synonyms in the Admin app with the Microsoft SQL Server database
In testing we found that counts for the frequency of Synonyms terms in the documents can be very slow when using the Microsoft SQL Server database. This was due to some configuration settings that required changing. If a similar issue is experienced we recommend following the directions specific to SQL Server in the Installation Guide.
Slow Query Performance
If Solr appears to be working very slowly despite fast disk access and enough memory, the performance may be improved by increasing the size of segments in the index. To do this, you’ll have to adjust your settings, re-index your data, and then do an optimize. (You could try doing an optimize without re-indexing first; it couldn’t hurt.) Settings should be adjusted in the documents/conf/solrconfig.xml file, or the corresponding file for another core, if that core is having the performance problem. Example settings that have worked for other institutions are below:
<indexConfig>
<mergePolicyFactory class="org.apache.solr.index.TieredMergePolicyFactory">
<int name="maxMergeAtOnce">10</int>
<int name="segmentsPerTier">10</int>
<int name="maxMergedSegmentMB">100000</int>
</mergePolicyFactory>
<mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler">
<int name="maxThreadCount">1</int>
<int name="maxMergeCount">6</int>
</mergeScheduler>
</indexConfig>
<query>
<queryResultMaxDocsCached>200</queryResultMaxDocsCached>
<filterCache class="solr.FastLRUCache" sizes="512" initialSize="512" autowarmCount="0"/>
<queryResultCache size="1024" initialSize="1024" autowarmCount="0"/>
<cache name="perSegFilter" size="10" initialSize="0" autowarmCount="10" regenerator="solr.NoOpRegenerator"/>
<enableLazyFieldLoading>true</enableLazyFieldLoading>
<documentCache class="solr.LRUCache" sizes="512" initialSize="512" autowarmCount="0"/>
</query>
These elements (<query> and <indexConfig>) should replace or be merged with any existing such elements you may have in your solrconfig.xml file.
|
You can trigger an optimize by using a making a POST request to a URL such as the following:
https://localhost:8983/solr/documents/update?optimize=true&maxSegments=10Trouble connecting to the Network Query Coordinator (ActiveMQ) during Tomcat startup
If network features are enabled but not functional on the EMERSE installation, you may see the following error message in the Tomcat log file:
ERROR: [2021-09-23T12:38:17,639] org.apache.activemq.util.IntrospectionSupport.setProperty()191 Could not set property host on Socket[unconnected]
java.lang.reflect.InaccessibleObjectException: Unable to make public void sun.security.ssl.SSLSocketImpl.setHost(java.lang.String) accessible: module java.base does not "exports sun.security.ssl" to unnamed module @1d855fThe Java Platform Module System (JPMS) was introduced since Java 9. Not all classes in the JDK are allowed to be accessed due to the access-control boundaries defined by the JPMS and enforced by the JVM. In order to enable the access to the unexported types of some modules, Break encapsulation is needed through --add-export and
--add-opens, which are defined in JEPS 261.
For the error message above, the implementation in the ActiveMQ jar may invoke methods in the JDK that are not publicly available. Specifically, the module java.base does not "exports sun.security.ssl" to unnamed modules.
Therefore --add-opens=ALL-UNNAMED option can be used to grant the access to the sun.security.ssl package of the java.base module. ALL-UNNAMED here means that the source package will be exported to all unnamed modules (code on the class path),
whether they exist initially or are created later on.
This option shall be applied on the JVM that runs the Tomcat instance for your EMERSE installation. This is done through
the environment variable JAVA_OPTS which can be found in the Tomcat startup script.
export JAVA_OPTS="--add-opens java.base/sun.security.ssl=ALL-UNNAMED"Negative Ids in MS SQL
MS SQL sequences default to the smallest 64 integer value as the start value of a sequence. In our scripts, we try to be sure to specify the start value, but in past versions of our schema it didn’t. If you see errors large negative numbers, the solution is likely to restart the sequence generating them, and to re-id the existing records with positive ids. The root of the problem is that the frontend JavaScript code looses precision when parsing the integers, since JavScript only technically has 64 floating point numbers, so any integer outside +/-9,007,199,254,740,992 (=2^53) probably cannot be represented exactly in the front-end.