
This guide contains an overview of the components required for EMERSE to run properly.
Components
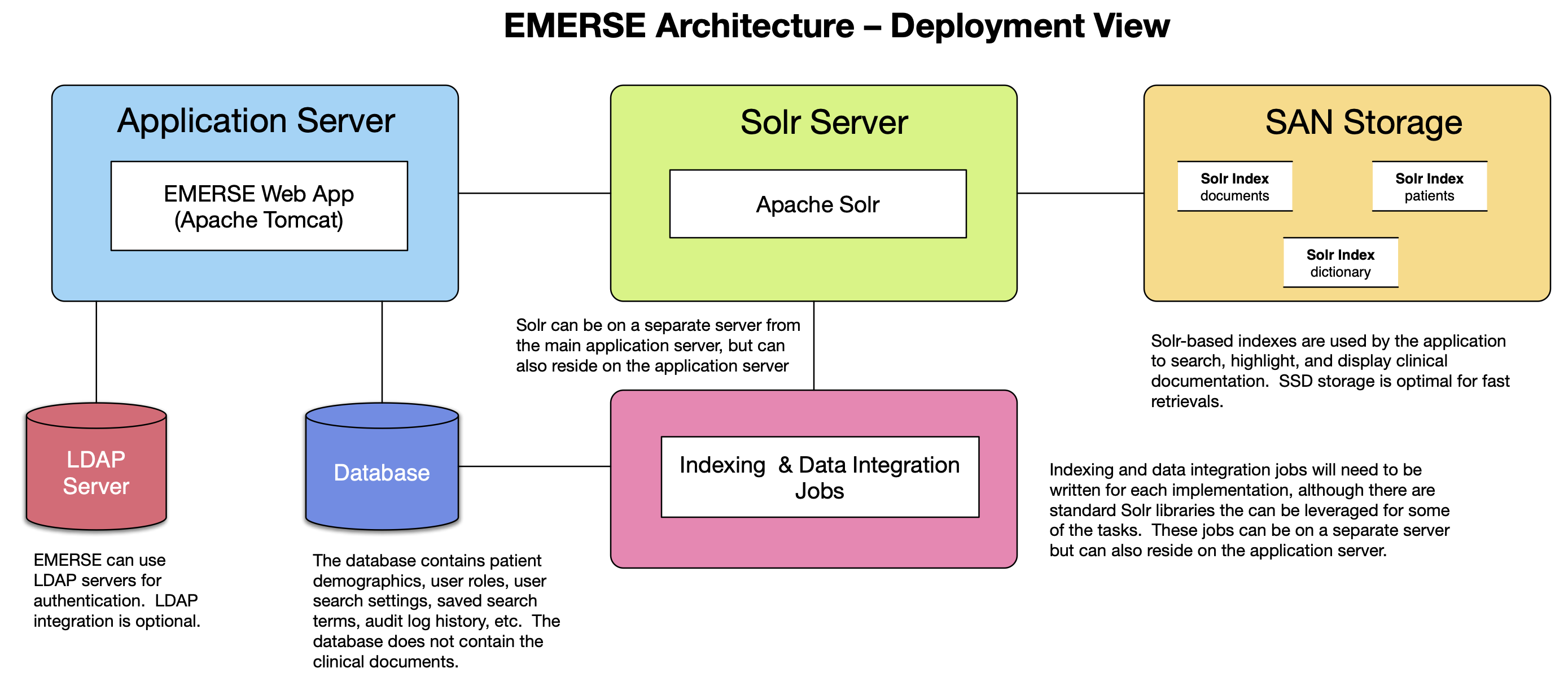
A fully functioning EMERSE system requires 3 main components:
-
The EMERSE application code, running inside Apache Tomcat
-
Apache Solr
-
A database
| EMERSE can optionally make use of an LDAP server for authentication. |
EMERSE application
The EMERSE application process is a Java based application. It is a standard J2EE web application that requires deployment in a Java servlet container such as Apache Tomcat running inside a Java Virtual Machine. We recommend using Apache Tomcat, as we have the most experience using it, but others such as Jetty could be used. Details on supported versions of Java, Tomcat and Solr are provided in the Installation Guide.
Apache Solr
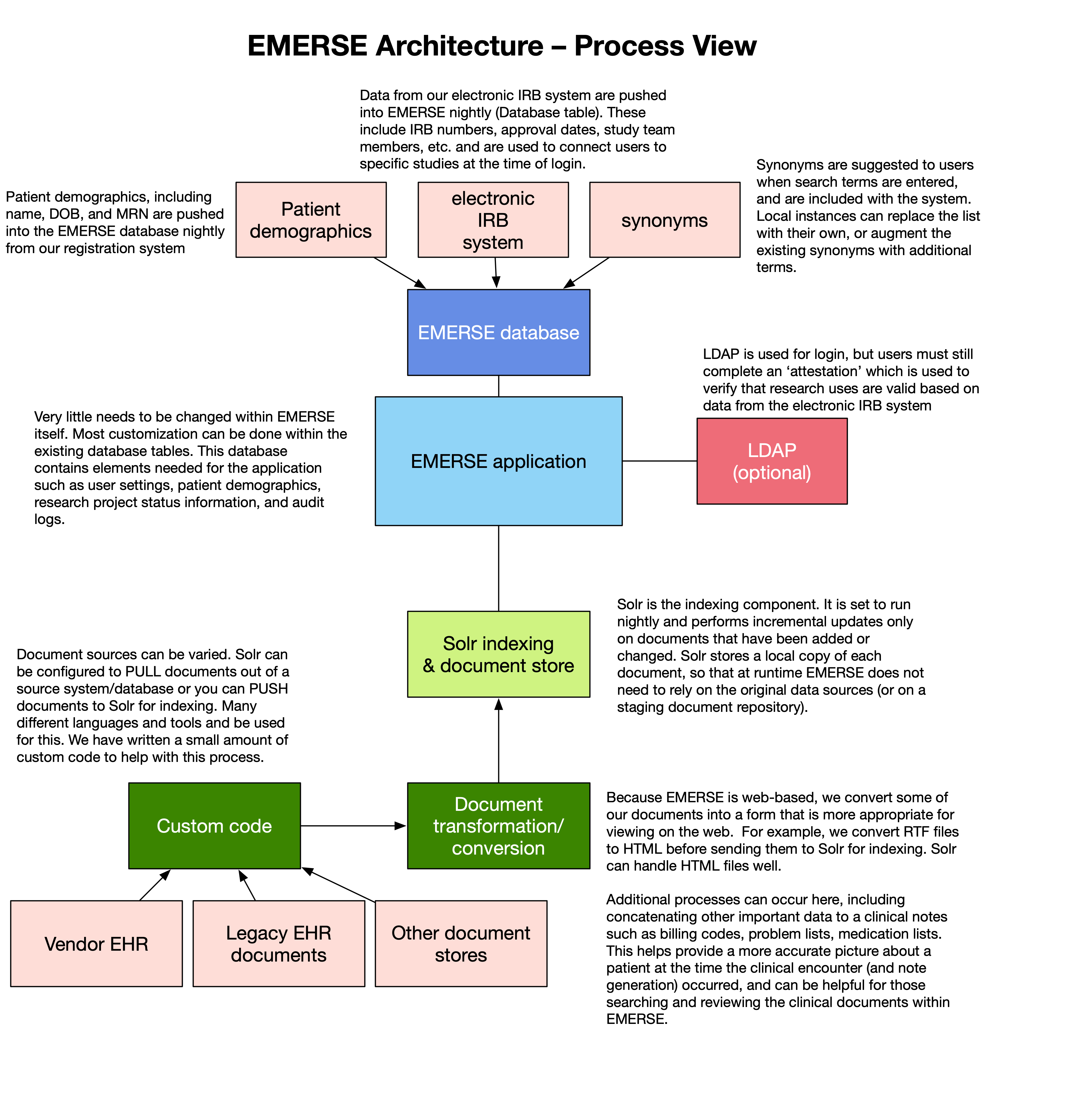
EMERSE leverages the Apache Solr project to enable searching of documents. Solr is a popular open source toolkit that enables fast searching and text retrieval by creating specialized indexes from documents. The EMERSE application uses these indexes exclusively to display, search and highlight documents. Therefore, to use EMERSE, a process needs to be implemented that will take documents from wherever they reside (e.g., electronic health record, document repository, clinical data warehouse, etc.) and send them to Solr for indexing. For more details on this process, see the Indexing code, below.
The Solr project umbrella includes REST based web APIs for querying, monitoring and admin tools, as well as the APIs for indexing and removing/deleting documents when necessary.
Database
The database stores audit information, user searches, patient lists, patient demographics, and some configuration data. The database does not contain the clinical documents or the index. Thus, searching and highlighting of documents occurs without the use of the database; rather, these features are mainly enabled through the use of Apache Solr. Additional information can be found in the Installation Guide.
Additional External Components
Indexing code
In order for EMERSE to highlight and search, documents need to be sent from their source locations to Solr for indexing. Because this process is likely to be highly dependent on local circumstances such as the location of the documents, it is not a core part of EMERSE and will have to be set up separately. Solr supports many mechanisms for receiving documents to be indexed, some of which are described in the EMERSE Integration and Indexing Guide.
At Michigan Medicine, a small Java application was created that pulls documents from various sources, then pushes them to Solr via the SolrJ API. Additional information on integrating your organization’s data with EMERSE can be found in the Integration and Indexing Guide.
Batch Jobs
Patient updating
The EMERSE software requires that patients and their metadata (e.g., medical record number, date of birth, sex, race, ethnicity) related to the indexed documents be loaded into a table in the database. At Michigan Medicine this is currently being handled by a daily batch job, using Pentaho Data Integrator (PDI). For every indexed document their should be a corresponding patient in the patient table, connected via a common medical record number (MRN).
Patient data stored in this table are then copied once per day to a Solr index, described in the Configuration Guide.
Research Studies and users
For auditing and access purposes it is helpful to be able to link a user, and a specific EMERSE session, to a study. Because most sites that support research have an electronic IRB system to keep track of studies and users, EMERSE can incorporate some of those data to be used for validating research study information after a user authenticates. For this to work, EMERSE requires that a couple of tables are populated related to research studies, and users related to those studies. Currently this is handled by a Pentaho Data Integrator (PDI) job that is not included with the EMERSE distribution, and this process will likely have to be customized for the specifics of your site and electronic IRB system.
Web Browser
EMERSE runs within a web browser, and although it may not seem like this point requires much consideration, it may be the case that your institution limits what browsers are available for use. EMERSE has been extensively in Chrome, and Chrome is the browser that we recommend using with EMERSE. It will likely work well with other modern standards-compliant browsers, but has not been tested. One important point to note is that institutions may sometimes have a 'compatibility mode' turned on with browsers like Internet Explorer so that it can work with older applications. In that case EMERSE may not work properly.
Document Repository
A document repository is recommended for EMERSE data integration, but not required. Documents get pushed to Solr for indexing, so from Solr’s perspective it does not matter where the documents come from. A document repository is not needed at run time for EMERSE, since EMERSE stores its own local copy of the documents (thus there are no real-time calls to the EHR or document repository when EMERSE is running). Nevertheless, having a document repository will be important if it becomes necessary to rebuild the indexes, or for comparing existing notes within EMERSE to any new notes that have been generated by the EHR. The structure/design of the repository will depend on local requirements, and some small amount of custom code will be required to retrieve documents from a repository and push them to Solr. Thus, the documents can exist almost anywhere, such as in a local data store, in the cloud, in a Hadoop cluster, etc. As long as there is a way to push those documents and relevant metadata to Solr, the actual source is unimportant.
Network
EMERSE also has an optional network that can link the systems in a hub-and-spoke model for querying across sites. Unlike local use where a user, given the right privileges, could potentially view clinical notes and protected health information, the network-enabled feature of EMERSE only allows for obfuscated counts to be transmitted across the network. Nothing else needs to be installed to use this network; only additional configuration is needed. Additional details can be found in the Networking Guide.